If SBOMs are a must, let’s make them as effective as possible

Since the announcement of Executive Order 14028, curiosity and confusion around SBOM (Software Bill of Materials) mandates has been widespread. SBOMs are indeed a jumping off point when it comes to the task of building an operational concept of software supply chain security, but there remains a considerable tooling gap that must be filled to operationalize them. Phylum is working to bridge that gap and help organizations draw real value from the SBOM model.
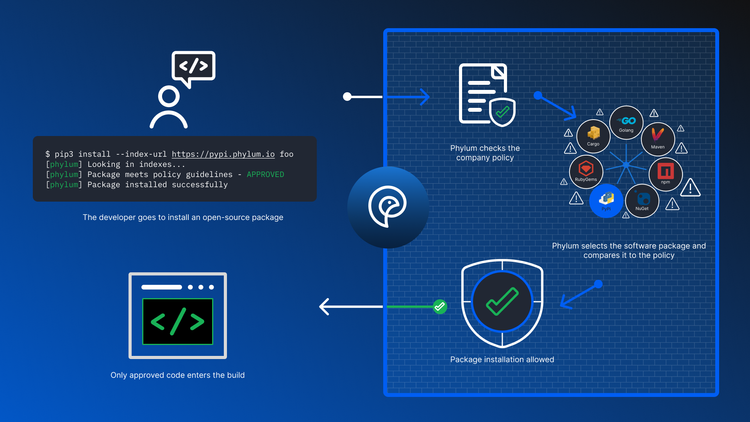
From SBOMs to Operational in under 5 minutes
Before exhaustively examining the current gaps and required features, it would be helpful to quickly summarize the format, what it provides, and more importantly, what it still needs.
SBOMs are fundamentally an inventory format for software - they are modeled after the types of deliverables that may be included in a physical supply chain, where a number of subassemblies are connected together to provide the whole deliverable. The notional idea is that a vendor should be able to provide such an inventory to a buyer (or end user) in order to give them a sense of what they are using, what it contains, and if it has any known security issues. Not only does this, at least in theory, give software consumers a way to reason about what went into a product or service they are using, just as the ingredients list on the back of a can might provide, but it also gives organizations a new lens through which to view third-party risk and vendor risk acceptance.
While this idea is great in theory, it has a number of issues (above and beyond those concerning accuracy, which is a whole different discussion). First, most projects of any real complexity have thousands of packages, and also come with thousands of security findings. Making sense of this at all will be extremely challenging, and create huge amounts of potential liability for the software publisher. Second, SBOMs often cannot be a snapshot in time artifact in the context of modern environments - imagine asking for the Software Bill of Materials for a service like Office 365 or the resources underpinning a web application running in AWS: a myriad of software products maintained by thousands of software developers, in which the final SBOM could change hundreds of times per day. On top of this, current SBOM formats (and other proposed frameworks, such as slsa) overlook other portions of the upstream “supply chain” that would be analogous to that of physical goods, but also present large parts of the overall attack surface - such as the “suppliers” (or, more accurately - package authors and maintainers) and the tooling/components/services that are leveraged in their production.
Ideally, to make these documents useful in the context of security and visibility, we need to fundamentally solve three key issues:
- Continuous Generation - In orderto represent what is “current,” SBOMs need to be both generated and available for each release. This means that for many large organizations applying modern industry best practices, they may need to be re-generated hundreds or thousands of times per day as things change.
- Contextualization - This represents the most immediate problem with current SBOM initiatives: How do you manage and utilize SBOMs received from vendors? A solution to ingest SBOMs and enable them to be searchable and provide the “nutritional facts” to go with the “ingredients list” is vital when considering how to manage massive lists that will continue to change and evolve rapidly.
- Automation - Given the scope and scale of the issue now faced by organizations trying to manage all of these deliverables, an ability to define policy and, as a supplier, attest to the policies and security practices applied during the development process is critical to both mitigating risk in a meaningful fashion, as well asproviding some level of confidence to buyers and end users that the product is stable and safe to use.
What Does SBOM Operationalization Require?
Now that we’ve done a short run-through of the current state of SBOMs and a summary of what we need to use them effectively, let’s examine the gaps (and potential solutions) in more detail.
Understanding the Intent
We have at this point rather exhaustively covered where the current efforts and formats fall short, but through what lenses can we view the SBOM where it could be helpful? There are really two different lenses to view this through:
- Internal Observability - Imagine for a moment that Log4J part 2 has now arrived. How can you quickly identify all places where you are impacted internally?
- Third-Party Risk Management - Now under that same scenario, what vendors do you use that may be impacted? This could include CI/CD providers, payment processors, and other third parties trusted with sensitive IP or customer data.
From both perspectives, SBOMs seem to be the start of a solution, even if they are incomplete today. The first step in getting from where we are at present to where we need to be in order to really operationalize these tools begins with better definition and tooling to help manage toward the above goals.
Addressing the Gaps
First, to apply the benefits of the above intents and start getting real value out of the whole SBOM concept, we first need to address the capability gaps in the format. This will, at a minimum, provide us with something against which we can apply real-world processes with some additional tooling.
Codifying Provenance
One of the first problems that emerges when looking at SBOMs in their current form is one of provenance. While they provide an inventory today, the inventory is woefully incomplete: most fields are optional, and many of the inputs - especially from places like version control system repositories - cannot be properly represented in the current formats. While some emerging frameworks (like slsa.dev) attempt to apply some additional notion of provenance, those sorts of artifacts are also incomplete. We must incorporate real provenance data into the SBOM format in order to really ensure that we get a reasonable view of what is actually inside the software we are consuming. This should notionally include (though is not limited to):
- Author Identity Information - While there is no way to make the data complete (due to the fractured nature of open source), authors - both maintainers and contributors - are a critical part of the software supply chain. They hold the proverbial keys to the kingdom and choose how the software we consume downstream is released. Even if complete data cannot be captured, we can absolutely do better than what is provided today, which is nothing at all.
- Development Tools - These include build tools, CI/CD infrastructure, and tools used during the development of upstream software. What good is securing your internal development infrastructure, if a compromise in any library you use could still cause an internal compromise? Additionally, this information must be granular enough to understand what version of each tool was used - simply collecting compiler flags is not enough. Oddly enough, while this vector of compromise was identified decades ago, we have still not taken the necessary steps to provide real protections around it.
- Controls and Protections were Used by the SBOM provider - If one of our goals is third-party risk management, what does the security posture of the development team look like? Is branch protection being used? What sort of review processes are applied? Etc.
- Artifact Attestation - For an SBOM to be usable at all, we absolutely must be able to tie an entry within the SBOM document back to an actual artifact. This should include both an actual build artifact, such as a compiled package, as well as continuously developed artifacts such as tagged branches in a version control system (more on this later).
Realistically, we must build an understanding of each of these elements to get a good understanding of what goes into the software we are utilizing before even considering how a bill of materials may be operationalized.
The Supplier Snag
Given that most of the current work around software supply chain security has been centered on adapting industry best practices for securing a physical supply chain, we’re left with a bit of a conundrum: not all of the analogies quite line up. Imagine, for a second, that you are sourcing materials for a manufacturing effort. Each of your suppliers will likely be willing to provide some guarantees, many contractually, to which you can hold them accountable. They will allow you to stay ahead of geopolitical risks and remain compliant with respect to sourcing from embargoed countries. Unfortunately, however, with software this becomes much more complex. In the case of open-source components, this is even more true - rather than relying upon trusted vendors, with whom you can establish a longitudinal relationship with, you are instead sourcing business-critical components from a scrap heap. Not only do these components generally come with no guarantees of any sort, but there could be any number of other issues in supporting production downstream - alignment of incentives, lack of control (or visibility) into their upstream “suppliers,” etc. Thus, we now must really enter a discussion around package authors.
The Persona Behind the Package
While really understanding the true identity of all authors behind the software we leverage is likely impossible, we minimally need to gain an understanding of their personas. This is important for a number of reasons: without this, we have no idea what their persona has done in the past. Even deceptively simple questions - such as how long have they been around? What other major projects have they contributed to? Are there major observable gaps in their public security profile? - are effectively impossible to answer with SBOMs in their current state, and few frameworks even capture contributors as a portion of the software supply chain. This oversight means that there is no mechanism to understand anything about who was involved, what their security posture and practices look like, and what their motivations might be (which, while certainly not visible in all cases, may at least give some insight into whether a component of your business-critical software stack is maintained by a well-funded company, a disgruntled, lone contributor living in Russia, or any gradient of possibilities in between.
What’s In the Toolbox?
What tools went into the production of this software? This is a critical question to answer, as it has been the source of a broad spectrum of CI/CD based attacks in the last few years. From SolarWinds to Codecov, development tools have contributed to a variety of compromises already - and while many organizations are considering solutions to protect their internal CI/CD and development processes, limited options exist, and this unfortunately does not cover third-party assets at all. To make the point of this clear - A development tool or CI/CD compromise anywhere in the software supply chain represents a compromise for everything downstream. This is a huge gap in the current SBOM ecosystem, and even newer efforts to codify provenance miss the mark - capturing woefully incomplete data about the tooling used to produce software. How can we claim provenance here if all we are capturing is the first level of CI/CD and compiler flags, but not capturing what compiler was used, or what components the CI/CD infrastructure was built with?
Control Certification
An additional gap centers around an understanding of the security posture of the software being managed via SBOM. This understanding of what security controls are in place is critical for both the third-party risk management use case, where we need to be able to glean insights into what risks we are exposing ourselves too by adopting these third-party assets. This sort of use case is mirrored in many modern security industry trends: SOC2, for example, provides this sort of information from a broader lens.
As a more concrete example of this, we can consider efforts like the OSSF Scorecard: despite being relatively simplistic (and opt-in), efforts like it are a start to gaining some of these insights.
Artifact Attestation
Finally, there is an unfortunate tendency with current SBOM development and generation to focus on producing a big list of findings… but there are very strict limits on how we can tie an SBOM back to an actual piece of software. In current leading standards like SPDX, even things like cryptographic hashes, a mechanism that would at the very least allow us to do some sort of positive matching between the end deliverable and the SBOM, are optional. This makes the framework useless - how can we take for granted that the SBOM represents the deliverables it claims to cover if we have no mechanism to validate that the two match?
The solution is clearly to provide more controls to manage package validation, and ensure that the thing we have in our possession maps back (with at least a small degree of certainty) to the SBOM we are currently observing. While this is a difficult problem to tackle with certainty (for many reasons), we must minimally force capture of file hashes and source file hashes (or at the very least, commit hashes from a version control system, such as git). This gives us a path to at least attempt to track back where the software originated, which with the current format is all but impossible.
While it seems at first like this might simply be an edge case that’s convenient to ignore, that is unfortunately not the case, as evidenced by the fact that many build systems allow direct references to some of these external resources - which are functionally opaque today, as they cannot be effectively represented in current SBOM formats without a great deal of additional work.
Tooling Requirements
Now that we’ve covered some of the current gaps we will need to address in the fundamental SBOM format to start really addressing security issues, but this alone won’t solve the problem. SBOM as it exists today is a bit like an ingredients list without the nutritional facts: while many tools can produce an SBOM, there are no guidelines about what to do when either one is generated, or when receiving an SBOM from a vendor or build.
Observability Capability
The first big capability that needs to be provided in order to make SBOM consumption feasible is one of observability. In theory, this should be the backbone of SBOM production, but unfortunately, there are no real tools that consume produced SBOMs to make them useful in this capacity.
So what does observability mean in this context? In modern organizations, as software development occurs, there are probably almost none (if any really exist at all) who could tell you at any point in time what their entire software stack is composed of. This became very apparent as the news around Log4J broke - organizations around the globe were scrambling to not just remediate Log4J related issues, but first to understand if they were even impacted.
This problem gets even hairier when receiving an SBOM from third-party vendors - now you should theoretically have the ability to understand if any of your vendors are impacted by a software supply chain-related issue, but how can that possibly be managed across an enterprise? Even the base case, which is to say, getting internal visibility is already tough, so adding the management of SBOMs - let alone transitive SBOMs (that is, the vendor SBOMs of your vendors, and then, the SBOMs of your vendor’s vendors, and so on) - the whole thing now just becomes a huge mess to manage.
While SBOMs should fundamentally pave the way to improved visibility, both internally and externally, there are some major capability gaps we must address in terms of available tooling to make this a reality: Not only do we need to make this huge mess of SBOMs searchable, but we also need the “nutritional information” - and with that, the ability to bake in policy about what is or isn’t allowed.
In an era where everyone is scrambling to even address trivial issues, and capable talent that can carry the appsec baton is beyond reach, technical controls are an absolute must.
Not Just a Snapshot in Time
Finally, one of the biggest challenges with broad SBOM adoption has to be managing against continuous delivery: an SBOM gives you a peek into the bill of materials as a snapshot in time (though truthfully, as discussed above, it really doesn’t even provide that in its current form). In order to really be meaningful, SBOM must have the ability to be delivered and accessed continuously.
Consider for instance, that you were to receive a vendor SBOM from your cloud storage provider: Not only would this (at the very beginning) be a document containing tens of thousands of individual pieces of software, but it would also contain many multiples of versions of those software packages. Now consider that by the time you receive that information it is likely already out of date: large enterprises often ship hundreds or thousands of builds per day - meaning that by the time you have processed, consumed, and reasoned about an SBOM for any large vendor, the data is already stale.
Versions will have changed, new packages will have been added, and some may have been removed. Modern development best practices mean that builds and delivers are meant to be continuous - which means faster iteration and faster release cycles, but also means that the delivery of a single SBOM is all-but meaningless. What this really implies is that there is a strong requirement for scalable automation around SBOMs in order for them to provide any value whatsoever - so each build would result in the production of a new SBOM that could be accessed and reasoned about by users.
This also - yet again - underscores the need for better automation: If it is a struggle to reason about internal software, and a bigger struggle to reason about internal software and external SBOMs from thousands of vendors, what does it mean when you have to deal with internal software, and thousands of SBOMs from thousands of vendors every day? At that point, the delivered SBOMs become worse than valueless - they simply become empty noise.
Filling the Gaps
Here at Phylum, not only will we soon be the first vendor to consume SBOMs and provide the missing “nutritional information,” from our comprehensive risk analysis (across all five domains), to our holistic understanding of provenance. we are also working to extend our current capabilities to enrich existing SBOM formats with the missing information required to make informed risk decisions around your software supply chain.
Additionally, we have prioritized baking in policy and governance automation from the very beginning - as even when the company was founded, the volume of software organizations need to wade through internally before even considering SBOMs from third parties is all but impossible. This enables real, at-scale analysis of SBOMs both internal and external - and paves the way to continuous SBOM management and the ability to set automated policy around delivered software assets - both internal and external - reducing risk, increasing velocity, and provided a real, scalable process.
The TL;DR
While SBOMs are certainly a starting point in the process of creating an operational concept of software supply chain security, there is a massive tooling gap that exists in order to operationalize them. Here at Phylum we’re working diligently to bridge that gap, and enable organizations to extract real value from the regulatory requirements that they are now beholden to with the regulatory shifts that have occurred over the last year. Contact us to discuss your unique SBOM needs.