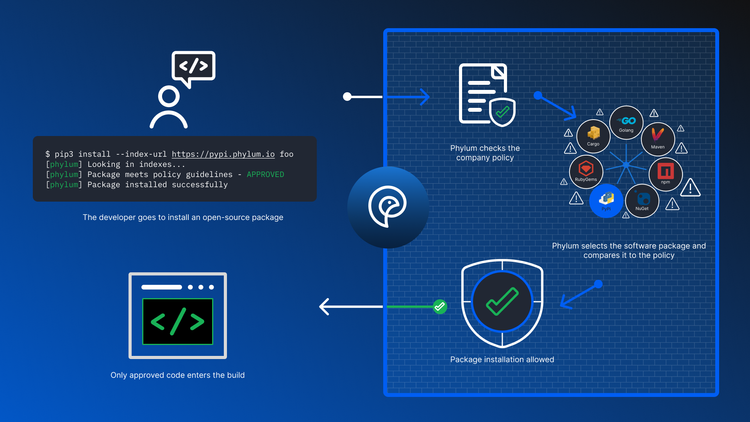
Design Matters: How We Created Phylum’s Risk Score for Open-Source Packages
Generating meaningful scores for open-source packages is extremely complex. Effective scoring for risk and reputation needs to incorporate disparate pieces of information while also accounting for important edge cases. The key challenge is to ensure that the score is:
* Maintainable - as time goes on and more attributes are incorporated, the score should become more accurate, not less.
* Intuitive - it needs to align with user expectations.
* Understandable - as above, it should be easy to understand how the scoring mechanism works.
* Useful - the scoring mechanism needs to provide utility and be actionable.
Edge Cases
Each software project will incorporate many packages. More importantly, each of these packages will incorporate many other packages, which are tied to numerous other packages, and so on. In practice, we need to generate scores that reflect the incorporation of the reputations of thousands of bits of upstream software.
More complexity comes from “non-standard locations,” which are places outside of conventional package managers that software gets pulled from during installation and build processes. This might include Version Control System (VCS) repositories like Git repositories (e.g., a package may pull a branch directly from GitHub when installed), direct downloads from third-party hosting or other similar configurations. Non-standard locations present significant complications. How do you incorporate reputation into something that is entirely author-maintained and is subject to change at any time? How often do you check for changes and updates while maintaining some record of whether changes have been made?
We need to be mindful that not all “findings” or attributes should have an equal impact on the score. It's an important consideration as we think about the aggregation mechanism chosen. In some cases, findings should only modify the score a small amount. Low-severity vulnerabilities or several open issues on the package project may be factors that do not create a huge problem unless a large volume of them exist. There are some findings, however, that users will always want to know about. If active malware, severe vulnerabilities, and similar attributes are present, they should have a major impact on the resulting score.
Packages vs. Projects
Further questions emerge when considering how to display and manage scores between a whole project and individual packages. How should findings for packages be tracked? When looking at the whole picture, we must incorporate the recursive relationships between all of the dependencies upstream into the score or else it would not be useful.
How should each package incorporate all of its upstream findings? How do we convert these aggregated scores back to an action that the end user should take? The answers to these questions pose additional engineering challenges, and there are significant tradeoffs to consider. While it may seem intuitive to make scoring recursive from each package, this approach has substantial drawbacks. In addition to the performance and scalability considerations that come with recursively scoring each package (in addition to the aggregated project), it makes findings non-actionable. Major findings will typically come from a minority of packages in the upstream dependency list. If we bundle each score from each upstream package into every step, we create a ripple effect in the dependency tree and make root cause analysis more difficult for the end user. This is amplified by the connectedness of the open-source ecosystem. Many packages share upstream dependencies, which further confuses the matter. In addition, most modern package managers support mechanisms like semantic versioning, which may make scoring packages in a vacuum impossible. For this reason, we can’t know a priori what all the upstream dependencies will look like for a given package without additional context.
To address the above issues and to keep insights useful, actionable, and easy to understand, Phylum chose to create clear delineation between packages and projects. Packages are scored individually and projects aggregate the scores of dependent packages recursively, allowing us to both comment on the project’s overall reputation and “risk” as well as identify with precision which package(s) are problematic.
Aggregation Functions
To generate risk scores, we could apply a projection from a high-dimensional space consisting of features extracted from a large list of packages. Alternatively, we could leverage data that would strongly predict the functionality of a given package, such as APIs consumed for example, to try clustering. Unfortunately, when considering the results that these approaches would actually produce, in all cases you would effectively get back a number that would be essentially opaque. How would you unwind the specific findings that you care about (not to mention their respective impacts) from a projection or a cluster? As a result, we opted to take a different approach. We could also consider generalized mean functions. In this case, we can aggregate findings and provide a single-value score. These mechanisms are both well understood and well documented. A few challenges, however, persist. We need to make sure that significant findings have a big impact on the score even when there might be thousands of other packages to consider. We also need to make sure that the score we provide back once again meets the criteria of being actionable and useful.
Weighting and Scaling
At Phylum, we apply a two-part scoring mechanism:
* We break out findings into five domains: vulnerability, license, engineering, malicious, and author. We compute the score for each domain.
* We then aggregate the domain scores into a single, final value.
Even though we differentiate between packages and projects, we apply the same general principle. There will be different volumes of findings that need to be aggregated. When calculating the per-domain score computation for each package, we start with a set of continuous values (0.0-1.0) returned from each finding. To satisfy our requirements for scoring properties, we want to aggregate the scores in a way that will allow us to handle very large volumes of findings so that critical issues have a large impact on the resulting score but low-severity or informational findings don’t significantly modify the outcome, except perhaps in volume (e.g., a large percentage of examined packages have medium-severity vulnerabilities). Due to the sheer volume of software most real-world projects pull in, there will almost always be some findings. While the findings should generally be shown to the end user in some form, they need to be weighted appropriately. We absolutely do not want to break builds for unimportant issues. To satisfy this property, we examine the harmonic mean. This is a concave function dominated by lower values. If our set of findings which consist of values between 0 and 1 has low values, it will disproportionately pull the overall score down. This means that a severe finding, which indicates that a particular package is untrustworthy (e.g., the finding returns a very low score), will have a big relative impact on the overall domain score. The approach is used in several other related single-value scoring mechanisms, such as generating an F1 score for evaluating the performance of a machine learning model. At Phylum, we leverage the harmonic mean again to combine the scores of the risk domains to produce the overall summary value.
Importance of Risk ScoringGiven the complexity, why bother with a score at all? Single-value scores provide an intuitive way to understand whether what the user is viewing is “good” or “bad”. It should be easy to interpret if the scale is well understood, easy to plot and track over time, and a common paradigm in other areas. In addition, modern software development practices favor automation. Requiring human intervention for every issue discovered does not work when hundreds or thousands of builds run every day, especially when there will always be findings given the volume of software involved. We need to be able to rank and score each reputation component for each package and aggregate them in a way that will provide a meaningful single-value score for a given project. Furthermore, the scoring system must be stable enough to build policy around it.