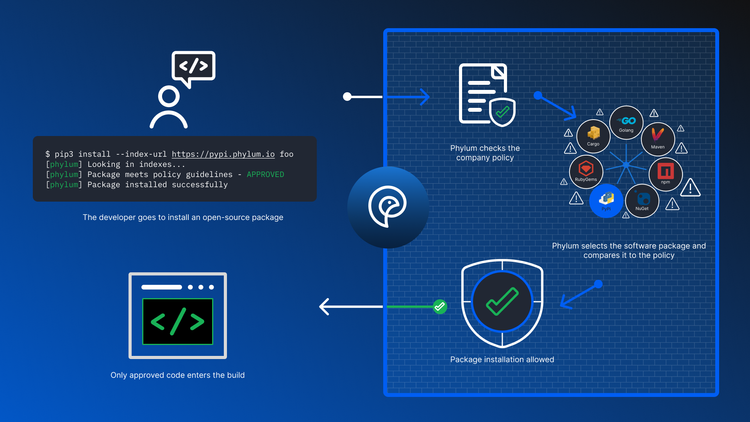
Internally Hosted Dependencies: A Losing Battle

There are well-known issues and uncertainties that come with third-party dependencies such as stale libraries containing vulnerabilities, malicious authors, and poorly-vetted contributions. As a result, many organizations seek to alleviate risk by auditing source at import time and then internally hosting the packages. While some classes of attack can be mitigated this way, the approach is far from comprehensive, and it may even create an entirely new class of issue: dependency confusion.
A Broken Security Model
Simply scanning dependencies, freezing versions, and trying to isolate by itself doesn't really solve the problem. First, issues in the frozen package versions will remain issues forever or at least until the packages are updated. Second, even the most thorough audit is likely to miss things given the sheer volume of software involved. With tens or hundreds of thousands of dependencies, a manual audit will have limited effectiveness. More importantly, a manual audit cannot keep pace as packages all independently shift and update over time. Additionally, vulnerabilities that aren't tracked in a well-structured feed like the National Vulnerability Database and also malicious packages are likely to be totally missed.
From Bad to Worse
Beyond targeting third-party libraries, hosting libraries using internal mirrors without additional controls can open organizations up to attacks from external entities. Dependency confusion allows bad actors to emulate internal software packages to gain access to developer workstations and critical build infrastructure.
In addition to packages that are purely open source software, most organizations also maintain packages that are meant only for internal consumption. This simplifies collaboration between teams and helps improve the reusability of proprietary libraries. While it is generally a best practice and a behavior that should be encouraged, the problem arises when these internal package names become leaked.
The Structure of the Attack
The opportunity for exploitation starts when a potential attacker identifies a package being used by a company in some sort of public asset that isn't published in an existing package repository. The attacker then publishes a new package in the public repository that has the same name as the private one.
How does having a public package that happens to have the same name as a private package lead to a compromise?
Generally, a package manager will attempt to pick the newest version of a package that will satisfy a particular dependency. Let's say that we have an internal package that our production software relies on. We'll call it "bar". Since this package is used by quite a few teams internally, we've hosted it in our on-premise package mirror. In this case, however, there is no public version of "bar." The only package named "bar" is our internally hosted, used-by-many-teams package. As such, this package is managed by an internal team and has relatively infrequent releases. We'll say it is at version "1.0.0". In this case, we have production software leveraging "bar@1.0.0." This is our internal-only package "bar" at version "1.0.0". As some time goes by, perhaps we open source some components and put them on GitHub or we simply have a reference to "bar" in our public software.
What happens if someone notices that we're using bar, but that it isn't a publicly-available package?
Nothing might happen initially, but now let's suppose that this person publishes a public package named "bar." Instead of doing what our internal bar does, it installs some malware on the system it runs on and allows the publisher to gain access to developer credentials and resources. This new developer begins to move the version of the new public "bar" package up. Once we have a public "bar" with a version greater than "1.0.0," which is our internal bar's version, something interesting begins to happen. As mentioned earlier, package managers often try to match the newest version of a package that will satisfy the dependency requirement. We will now end up with the public "bar" and along with it, a major security incident.
Managing Against Dependency Confusion
While it is technically possible to say that you should simply scrub references from internal packages from the internet, this is likely extremely difficult in practice. The first line of defense is generally in the development shop itself. The foundation of a bad actor being able to successfully exploit a state of confusion between internal and external packages relies on how software developers within the organization have configured their projects. Most package managers rely on a file that outlines the dependencies for the project.
For example, requirements.txt or package.json outlines the packages the project depends on and what versions will satisfy the requirement. While technical controls and capabilities speak to this issue more generally, the first step to solving dependency confusion is to be specific about which version or versions of a given package should satisfy the dependency. This is especially crucial moving forward. There are very likely other risks in this realm that aren't yet well understood.