Using Entropy to Identify Obfuscated Malicious Code

In a typical software program, a lot of information can be determined about a program by simply examining the strings that it contains. For example, you can see the files that the program uses, network addresses or hostnames, environment variables, and runtime libraries. Of course, these are easily discernible with static analysis programs, but even simple utilities like GNU strings are well suited for examining them.
To avoid detection, certain authors might wish to deliberately obscure the nature of a program by rendering these strings less transparent.
While there are some legitimate cases for doing this, malware often attempts to hide its activities by obfuscating data, strings, and functions in the package source code. This inhibits analysis of the application by masking critical mechanisms that the malicious code uses to operate.
In the modern world of software engineering, a great deal of code that is executing on a user’s machine, whether in the browser or as a standalone process is dynamic, interpreted code . In general, this means that the running code starts out as human-readable text. From a certain point of view, the entire program is a string which makes it trivial to determine what the program is doing.
JavaScript running in the browser has proven to be especially fertile ground for obfuscation. A common malicious use case is simple: obfuscate malicious code entirely and then deobfuscate it at runtime before executing it by a simple call to `eval()`.
The obfuscations used in such situations are typically trivial to unravel, leveraging lightweight common encodings like base64, url-encoding or a simple XOR transformation, rather than using actual encryption. This often, though not always, results in strings with higher entropy. In a nutshell, entropy is a measure of the information density or average level of information contained in a given string. While the presence of high entropy or encoded blocks of data are not indicative of malware generally, nearly all malware will include some encrypted/encoded data blocks.
Some Common Encodings Used for Obfuscation
To illustrate the above, we measured the entropies of strings obfuscated using some various common obfuscation techniques. The original unobfuscated string was one paragraph “Lorem ipsum” text with Shannon entropy of ~4.179.e
|
Obfuscation Scheme |
Entropy of the Obfuscated String |
|
Base 64 encoding |
5.320 |
|
RC4 encryption |
6.107 |
|
URL encoding |
3.094 |
|
XOR (single char key) |
4.179 |
|
XOR (multi-byte key) |
5.244 |
For the only actual encryption scheme used (albeit a deprecate and relatively insecure but convenient one), RC4, the entropy is much higher than the original source string making it quite easy to pick out. This is to be expected. Additionally, base64 encoding results in significantly higher entropy than the source string.
Unsurprisingly, XOR-encoding of the string with a single char value results in the obfuscated string having the same entropy as the original string. This is a one-for-one replacement mapping of source characters to encoded characters.
Of the common schemes above, only URL encoding results in an encoded string with lower entropy than the original string. As a result, it may prove useful to consider code samples with strings that have an average entropy that is significantly lower than what would be expected.
A Real World Example
Obfuscated strings appear across most JavaScript exploit kits. The goal is to hide behavior. The screenshot below is taken directly from a recent sample of malicious code used to skim credit card information by impersonating a Google Tag Manager Script.
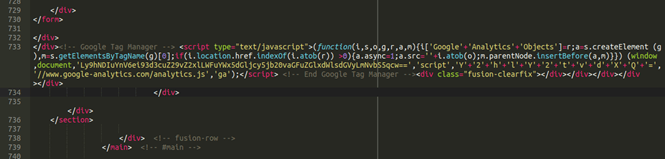
The long string in yellow obfuscates a known malicious url. These sorts of items are identified by this heuristic. The entropy of the encoded url is approximately 5.0, while that of the original string is significantly lower at around 4.5.
Importance
Large numbers of obfuscated strings are uncommon in benign software. By examining the average entropy of strings within a given piece of code and by comparing it to the expected entropy for similar bodies of text, we can identify potential malware behavior for further analysis.
Phylum’s Approach
Phylum’s technology identifies obfuscated data in the source code of customer dependencies. If the volume of obfuscated blocks exceeds the requisite threshold, it will negatively penalize the Phylum Package Score. The presence of encrypted/encoded/obfuscated strings is not, by itself, indicative of malicious behavior. However, it is an interesting data point to consider. Large numbers of obfuscated strings will have a moderate affect on lowering the package score.