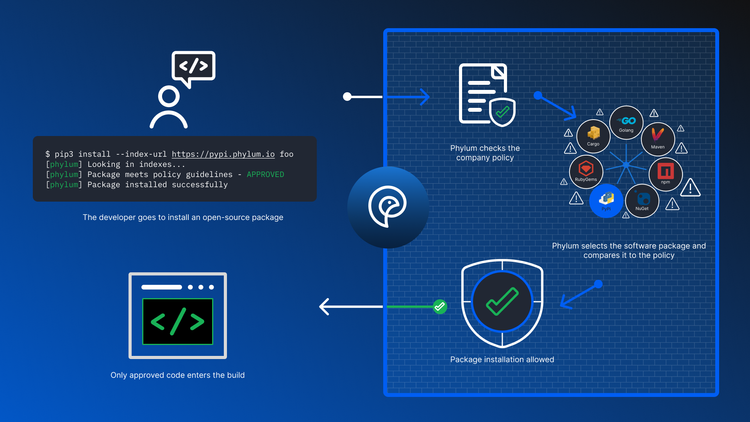
Vulnerability Reporting Has Fallen Behind

There has been an explosion in new software over the past 3-10 years. The amount of new software released and the number of new software developers entering the job market has increased dramatically. The associated impact can be observed from statistics on GitHub, which is currently the dominant leader in source code management and hosting.
Sparked from a conversation with a previous co-worker (Hi, Phil!), we dug into the data of identified software vulnerabilities to see how the change in software development compares with the rate of vulnerability identification.
Software Multiplication
In 2009, there were a total of 100,000 repositories in GitHub. In 2020, the number grew to over 190,000,000 following a nearly exponential growth curve:
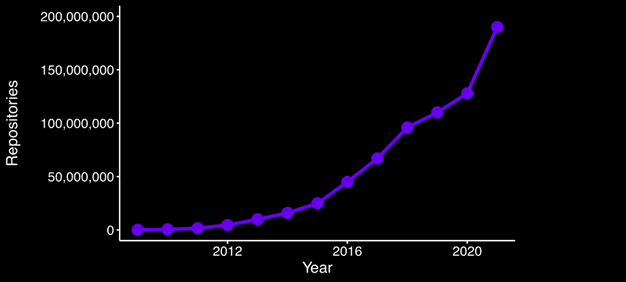
Figure 1 – Number of GitHub repositories by year
Vulnerability Reporting
Now let’s consider the pace at which vulnerability research progressed. While the amount of open-source software skyrocketed, the growth of reported vulnerabilities (as viewed in the National Vulnerability Database) remained relatively stagnant. In 2009, when GitHub had a scant 100,000 repositories, 5,736 vulnerabilities were reported.
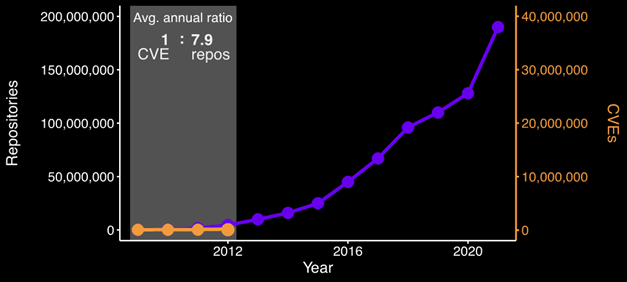
Figure 2 – Number of GitHub Repositories and vulnerabilities reported by year
We would expect that moving forward, we would see the growth of vulnerabilities track closely with the spike in software produced. It is highly unlikely that developers are suddenly producing software that is less buggy than projects previously produced.
We would generally expect the following:
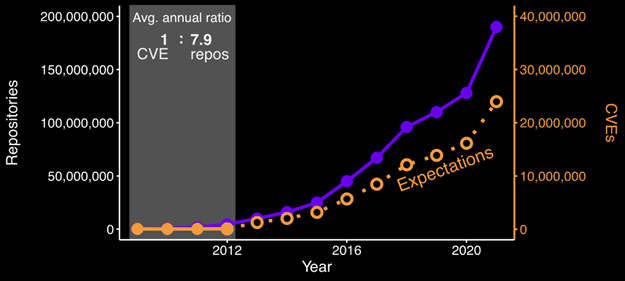
Figure 3 – Number of GitHub repositories and expected number of vulnerabilities by year
Instead of seeing vulnerabilities tracking with the volume of new software appearing in the open-source ecosystem, the number of reported vulnerabilities increased only a modest amount. In 2018, when there were 96 million repositories in GitHub, only 16,555 new CVEs were registered. This leaves us with the following growth curve:
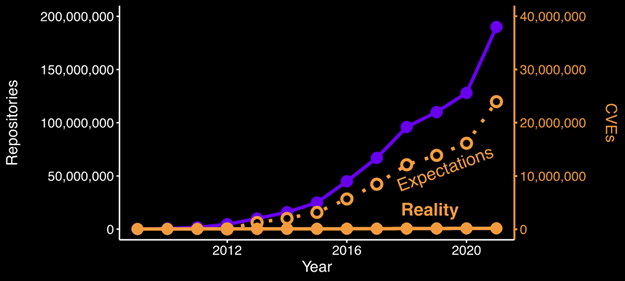
Figure 4 – Number of GitHub repositories compared with expected number of vulnerabilities vs. reality by year
What This Really Means
It is highly improbable that software developers have improved to the point that vulnerability growth simply tapered off. As a result, we are left with the reality that there are a massive number of undocumented vulnerabilities in the open-source ecosystem:
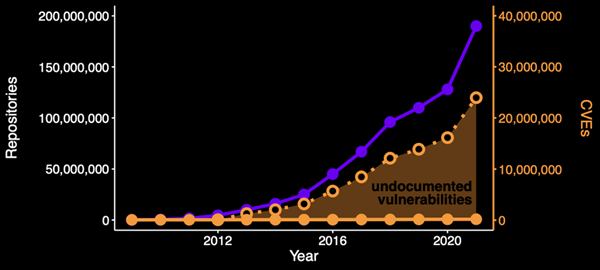
Figure 5 – Estimated number of undocumented vulnerabilities by year
The visualization aligns with sample studies that we have performed at Phylum. Out of a random sample of several thousand packages, our team conducted simple keyword searches and uncovered hundreds of well-documented vulnerability reports buried within software issues that do not appear in any published vulnerability database.
Ecosystem Comparisons
If nobody is actually using a software project, does the presence of security issues really matter? How many of those millions of GitHub repositories are real projects, as opposed to portfolio projects, class materials, or unfinished side projects? Interestingly, the growth curve is replicated in many package management ecosystems, which are all published software packages. Similarly, as we've written about previously, ecosystem-specific reported vulnerability counts have been lacking. NPM (as illustrated in the two articles linked above) has similarly grown from 12,000 packages in 2015 to over 1.7 million today, and the number of reported vulnerabilities is closer to 3,000.
There has been an explosion of new software engineers, with some putting the of software developers across the globe at around 24 million in 2019. Security professionals, conversely, face a huge labor shortfall, and had a scant 2.8 million professionals across the globe during the same period. Of that, only a small percentage are likely to have the necessary skillset for source code auditing to identify and report new software vulnerabilities.
As a result, it is unsurprising that reported vulnerability counts have generally remained the same year-to-year, while software counts, and contributions have skyrocketed. With this massive capability gap, new approaches must be leveraged to gain real understanding of the software supply chain risk, even when exclusively considering vulnerability identification.
Static analysis needs innovation to be scalable, performant, and accessible to everyone to protect the creation of software at current rates and those of the future. Anything short of this approach will result in a continuation of the same growth curve with published software growing at an unprecedented rate and identified software vulnerabilities lagging far behind.
At Phylum, our platform was designed to support both our iterative static analysis and dynamic analysis capabilities that allow us to improve on the state-of-the-art and meet the challenges presented by modern software development.