Hidden Dependencies Lurking in the Software Dependency Network

We are not the only ones with a social network! Much like we form social connections through friendships, software packages form connections to other packages through dependencies, when a package relies on another package to be able to run. For example, package A’s source code may load package B to do a specific task (e.g., read data from a .csv file), thereby creating a dependency on package B. Dependencies like this form all the time because software authors do not want to reinvent the wheel: why write code to do a specific task when you can quickly load and use another package that can do it for you? Thus, the modern open-source software ecosystem is a vast network of dependencies from one package to another.
Here, at Phylum, we use the dependency network to detect cybersecurity risk. After all, dependencies are often a main way that vulnerabilities and malware are introduced to open-source software projects: an otherwise benign package may inadvertently depend upon (and thus load) a package that has been exploited with malicious code.
In this blog post—the first in a series that will explore the open-source software dependency network—we will show that the dependency network reveals an overlooked reality in modern software development: if you are like nearly everyone else and rely on open-source software packages, your software project likely has far more dependencies than you realize.
So, let’s visualize the dependency network using the package data that we have in our platform database1. We constructed this package-to-package dependency network by collapsing all versions of a package into one node on the network. Therefore, we can think of a node as representing all versions of a package and an edge as representing a dependency that existed at some point. Importantly, edges are directed and indicate the dependency relation—e.g., if package A depends upon package B, it is represented in the network as A→B.
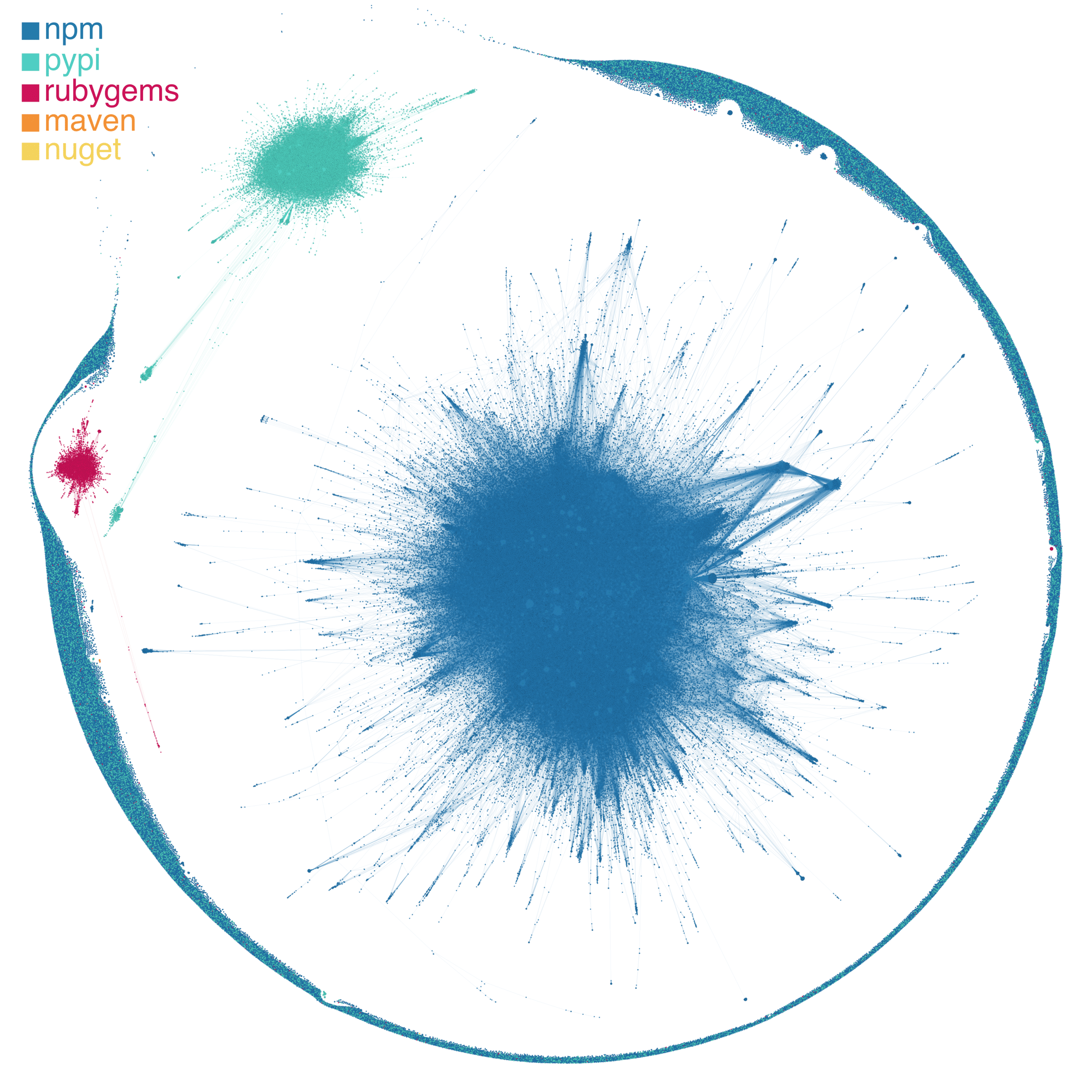
In the visualization of the dependency network (Figure 1), we see three main clusters representing the three large ecosystems—npm (javascript), pypi (python), and rubygems (ruby)—that we are currently focusing on. While there are certainly three large, highly interconnected clusters of packages, you’ll also notice the “asteroid belt” of largely single packages that circle the clusters.
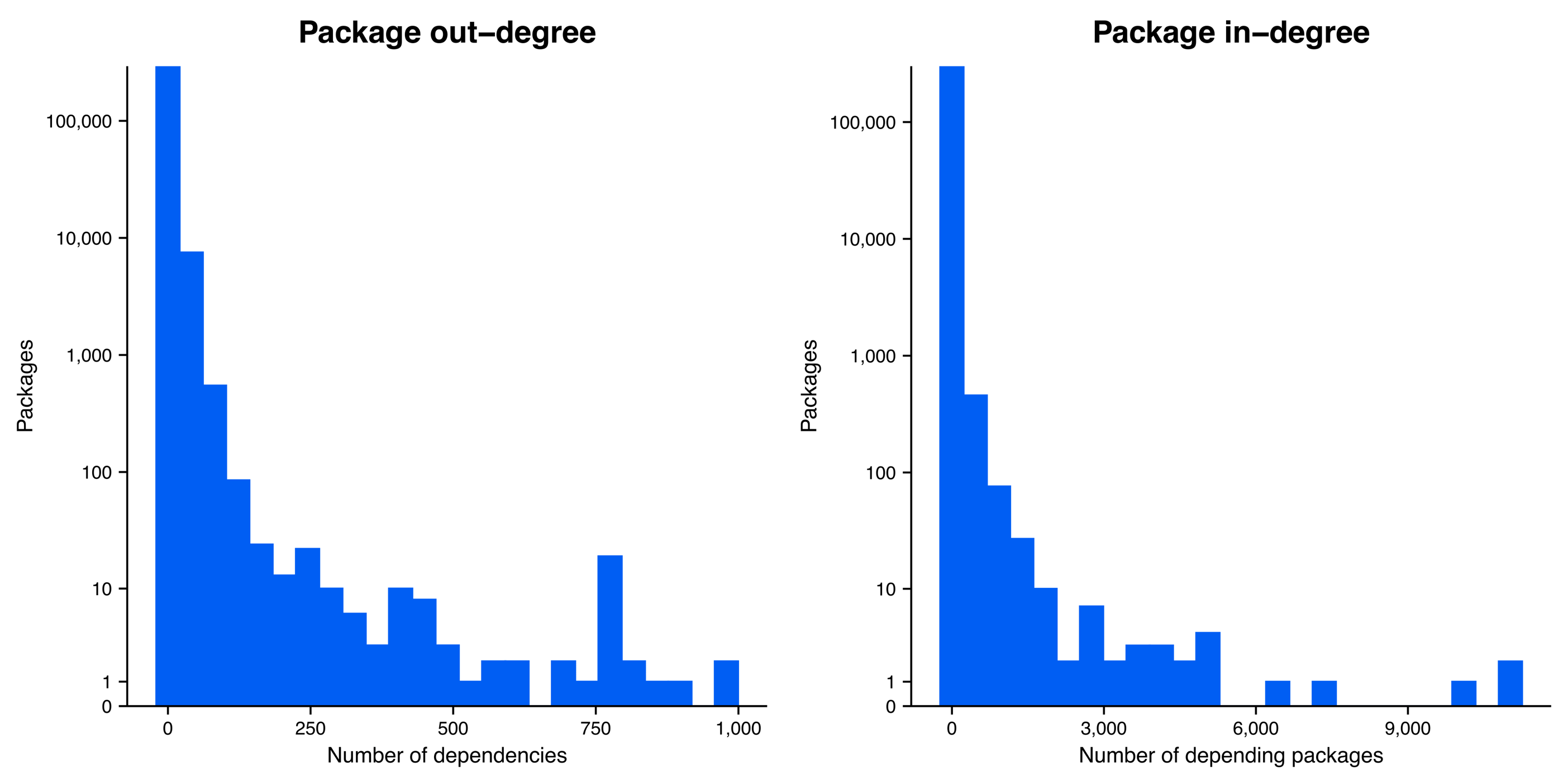
The large number of singleton packages in our network visualization highlights the fact that while software dependencies are ubiquitous, they are not evenly distributed across packages (Figure 2). In fact, 49.3% of packages have no dependencies and 62.2% of packages have no depending packages (i.e., the other side of a dependency: a package that depends upon it). Diving a touch deeper on these two statistics, we find that 26.9% of packages have no connections—in or out—to other packages. Still, among the remaining approximately three fourths of packages that have some connection to at least one other package, we see that the distribution of dependencies is highly skewed: many packages have a few dependencies or a few depending packages, while a few packages have many connections to other packages through dependency relationships. (This is a classic pattern in complex systems ranging from social networks to economies. In a future blog post, we’ll dive into the cool science behind this and what it means for the open-source software ecosystem!)
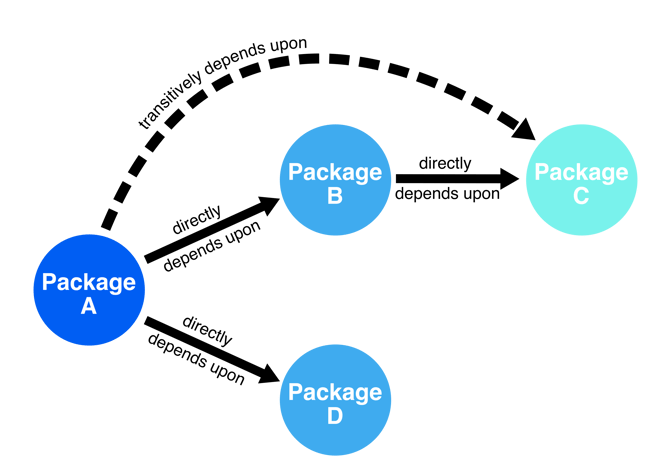
Counting dependencies like this only tells part of the story. Packages can directly depend on other packages, but they can also have transitive dependencies, in essence, indirect dependencies that are introduced by the dependencies of dependencies. In Figure 3, we see that package A depends upon package B, which in turn relies on package C. Therefore, when package A loads in package B, it also loads in package C under the hood. Thus, to get a true sense of package interactions in our dependency network, we also need to measure transitive dependencies like this.
When we account for both direct and transitive dependencies, we get a much different—if not a bit shocking—image of the software dependency network (Figure 4). We measured transitive dependencies up to 6 hops out from a focal package2. When accounting for direct dependencies—the traditional way of thinking about software dependency and risk in the cybersecurity industry—we see that all packages have fewer than 1,000 dependencies, with only a small handful of packages actually reaching close to that number; however, when we also account for transitive dependencies, the number of dependencies explode, revealing that many packages actually have thousands of dependencies.
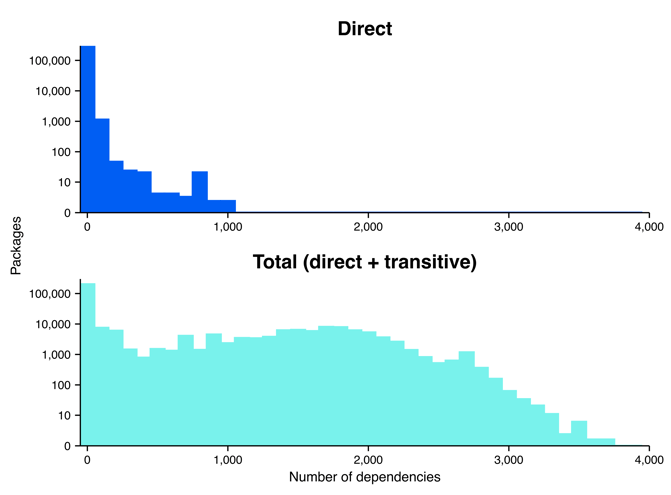
Well then, just how many transitive dependencies are lurking under the surface? Among packages with at least one dependency, the median package has 3 direct dependencies but 751 total dependencies when accounting for both direct and transitive dependencies (Figure 5). That is 748 transitive dependencies that are not accounted for in the mind of the developer!
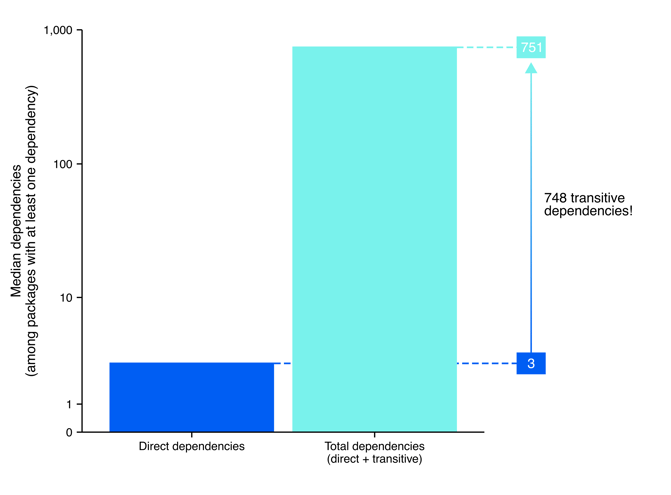
Of course, we should note a quick caveat to this analysis: as we mentioned before, our dependency network collapses all versions of a package into one node. Therefore, some of these dependencies will not be present in a specific version since dependencies evolve over time for many software packages. Still, we might reasonably expect a similar order of magnitude when considering the difference between direct and transitive dependencies for a given package version. Moreover, at the very least, this analysis shows the scale of interaction between packages over time, which drives home how we miss the true scale of cybersecurity risk when we only consider direct dependencies.
The good news is that new approaches (ahem, us at Phylum!) are pushing to capture the true complexity of risk in open-source software, like the true scale of dependencies—both direct and transitive. If anything, we hope this blog post simply emphasizes the true interconnectedness of the modern open-source software ecosystem. Of course, this interconnected nature is a double-edged sword: it can be exciting—packages adding exciting new functions and features by building off previous work—but it also introduces immense risk—risk that one increasingly needs cutting-edge tools to detect and mitigate.
Stay tuned for future blog posts in which we’ll continue exploring the dependency network!
Footnotes
1 Please note that while our database comprises a wide selection of packages—currently over 300,000 unique packages with dozens or even hundreds of versions per package—it is still an incomplete collection of all packages in the open-source ecosystem. Every day more packages are added to our database, but currently we are focusing our efforts on the javascript ecosystem (npm), followed by python (pypi) and ruby (rubygems).
2 While a full count of transitive dependencies will need to go 10-20+ hops out, each additional hop out in the network adds exponentially more computing time. Preliminary analysis suggests that 6-8 hops out in the network captures an overwhelming majority of the total dependencies in the network. Therefore, a 6-hop measurement offers a nice middle ground between accuracy and computational expediency.