The State of the NPM Ecosystem

What does the upstream for major packages really look like? Over the past few years, the shape of the open source ecosystem landscape has shifted drastically, exploding both in the volume of published code, and also the number of dependencies that live upstream from a given library.
Scoping the Discussion
In order to have a real discussion about software packages and ecosystem health, it's important to first understand the current state of the ecosystem. For the sake of simplicity, we'll keep the focus of this discussion to NPM - which represents the logical extreme of the problems and ideas discussed here. Keep in mind, however, that this is absolutely not exclusively a Javascript issue - a cursory glance shows that all of these problems are just as present and relevant in every other programming language ecosystem - even if the awareness is somewhat lower.
Some Background
In the 90's, the major trends surrounding software development all centered around one core concept: Code Reuse. While code reuse has probably been a part of software development from the earliest days of industry, the practices around this period began to favor it very heavily - during this decade, languages and APIs built around Object Oriented (OO) concepts started to really rise to prominence, and the earliest iterations of package managers were minted. Interface definitions and library packaging were at the forefront of the tooling. If we fast forward to the end of the 90's, specifically to the year 1999 - the year when The Pragmatic Programmer was published - we see this whole concept codified with the DRY (Don't Repeat Yourself) principle. This, to be entirely fair, is a great thing for software - reusing previously-written code (that has already been tested, validated, and vetted) probably saves billions in development costs annually. On the other hand, however, it does come with some implicit risks.
Software Reuse: The Implications
While all of this was not only very well intentioned, but also a generally smart way to think about the problem, the landscape has shifted drastically since then. Gone are the days when the people behind the software you consume as part of your build process are really understandable - the scope and scale of the open source ecosystem have ballooned over the last few years, and continue to do so at every turn. The implication here is two-fold: Firstly, it is difficult to really reason about what you are incorporating into your codebase when leveraging an external library, giving rise to a whole host of paid solutions that simply provide you with a "bill of materials," and second, there are a whole host of hidden costs bundled into the upstream packages and libraries. The technical debt contained in those packages becomes your technical debt, their issues (to varying degrees) become your issues. This also leads to a great deal of what-ifs: what if one of those packages has a critical vulnerability? What if one of them contains licenses that may impact your commercial viability? What if some of them are abandoned? Contain malware? Have backdoors?
The short answer is: All of these are valid concerns. Some of them have come to the forefront of the public focus (particularly issues around licenses and vulnerabilities), but as for the rest - they represent a veritable ticking time bomb in the community; one which has arguably gone off already in the form of 700 malicious RubyGems, hundreds to thousands of de-listed npm packages, and dozens of Python libraries, and tens of Docker images, among others (while I did promise up front that we'd be focused on NPM, it very much bears mentioning the scope of these issues in other, tangential ecosystems).
Rough Numbers
So even if we believe that all of this is a big issue, that begs the question: How big is it? Just to get a rough idea, this "State of the Union" post about NPM (published in early 2017) indicates that in 2015 - 5 years ago (at the time of writing) - NPM contained a scant 12,500 packages. Fast forward to today, and it contains nearly 1.4 million, and continues to grow at an average rate of almost 900 a day.
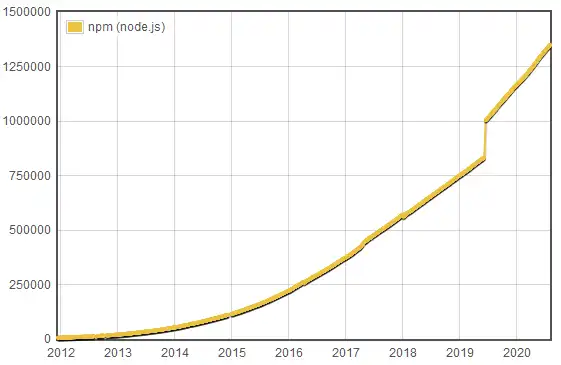
Keep in mind that this is net new packages - not at all counting updates to existing ones under active development.
What does this really mean, though? Do we really care about the size of the ecosystem if we only use one or two major packages during development? In order to get a better understanding here, we did some more detailed analysis on React (an immensely popular UI framework, for those unfamiliar) to figure out what its dependency graph looks like. A first pass at this seemed like a good spot to simply look at some products that do commodity "bill of materials" and vulnerability analysis. Picking a popular tool, we checked out the latest react build (at the time of writing), and looked to see what its dependency tree would look like:

At first glance, this doesn't really seem to tell the whole story; if we pull open react's package.json directly, we also see this:

The "devDependencies" are totally ignored! While this may not seem like a big deal at first blush (they aren't included in the final build, after all!), in many ways, they actually pose an even bigger security threat than the production dependencies. Production dependencies for React run in the web browser's sandbox - and while there is certainly a whole host of bad stuff that can be done there, dev dependencies have the ability to interact directly with the host they are running on without any sandbox, meaning they are free to access files, connect to remote servers, and run additional programs with the same permissions as the current user.
Really, at its core this means that fundamentally untrusted code, written by random developers, runs on sensitive systems where security credentials are stored, such as developer workstations, CI runners, and more. If stealing some customer data here and there from the browser seems really bad, what does the ability to steal any keys, credentials, and access that a developer or CI runner has the ability to access mean? Most developers have root access to their own system, and often have access to sensitive infrastructure and data, including production systems. CI runners are often worse - modern CI/CD processes frequently inject credentials to everything during the build and deployment process, giving an attacker the proverbial "keys to the kingdom".
To make matters even worse, simply looking at the package.json doesn't really tell the whole story - nearly all of the dependencies in that list in turn have dependencies, which in turn have more dependencies, and so on. If we pull down the entire graph just for React, we get something like 7,000 total dependencies for a single library.
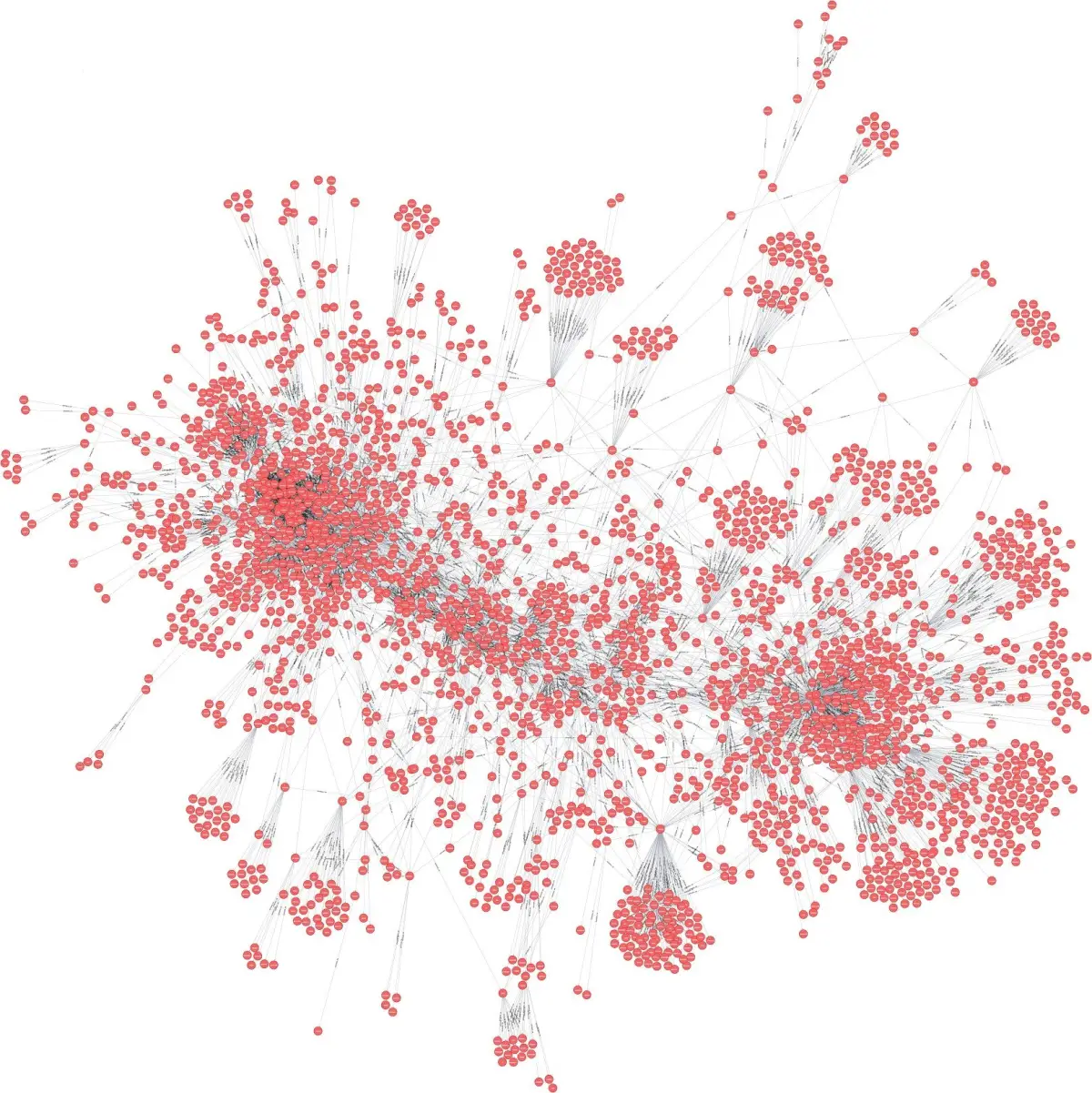
To be totally clear, this is not what you'll get every time you run npm install, but rather a superset of what you'll get during that process. Due to semantic versioning (notionally, the option to specify ranges of acceptable package versions in your package.json which will satisfy a dependency), it is all but impossible to say exactly what you'll get a priori, as large parts of the dependency graph may change substantially between package versions.
Really, all of this simply compounds the root problem: well meaning development principles have been pushed to their logical extreme. This ultimately makes simply understanding what you'll get with a given install an almost impossibly hard problem. This is doubly true if you want to develop anything more than a cursory understanding of the stuff that sits upstream from your development efforts - not mentioning the authors and maintainers behind those packages.
Not Just Security
While security concerns are certainly at the forefront of this discussion, a whole separate class of issues presents itself here: How does the code quality of upstream packages impact the technical debt of your projects? While this seems like sort of a subjective thing to measure on its face, some clear problems present themselves: Does the repository in question have good test coverage? Does it have unit tests at all? What about the contributors, how responsive are they to issues? How many contributors have the ability to commit code - if it is only one, what will happen if that contributor stops working on the project? And as a follow on, does the repository appear to be abandoned?
These are certainly all concerns for every consumer of open source - issues in any of these areas in a single library will be issues for every package that depends upon them.
It Only Gets Worse
While all of this seems bad enough, what about updates to those 7,000 existing packages? Even if we have undeniable proof that all of the authors sitting upstream are honest and well intentioned, what happens if they suffer a credential breach, like the relatively-recent one suffered by Docker Hub? Additionally, what if their account credentials are compromised in some other way? Either scenario puts every package downstream completely at the mercy of whoever obtains their credentials. This may seem like something of a hypothetical situation, but that is unfortunately not the case; doing some very high-level sampling of some top contributors (with hundreds of published packages, all upstream from dozens of major projects) and comparing the results with some major password breach datasets yielded disturbing results: the very first such contributor we looked at appeared in no less than three such datasets, with the same password in use in all cases - a password extremely vulnerable to dictionary attacks, no less. At this point, not only do we need to be able to keep track of net new additions to our dependency graph, but also any changes to the thousands to tens of thousands of libraries that exist upstream, as such changes may introduce malware (if the author's account is compromised, or even if ownership of the package happens to change hands), or add more new dependencies.
Where do we go from here?
We can certainly see at this point that there is not only a substantial hidden cost to integrating third-party code, but that the ecosystem itself has grown totally out of control. The risk incurred by bringing in thousands of third party dependencies for a single library is astronomical - especially when you consider that many of those packages (especially in the NPM ecosystem) are less than 5 (not 500, or 5k, but 5) Source Lines Of Code (SLOC) in length. While that is generally not a great measure of effectiveness, the risk/reward and maintenance trade-offs of incorporating libraries which have many times more text in licenses and packaging files (such as build files, manifests, etc) than what resides within the body of the package itself is absolutely terrible. This is many times more true when you multiply this risk by hundreds or thousands.
At this point, what do we do? Clearly the ecosystem has ballooned out of control, and no clear alternatives exist to leveraging open source libraries - in most cases, the cost of building a project from scratch is prohibitively expensive, and for all of its current flaws, the wisdom behind code reuse is certainly sound. A large number of tools exist that purport to do package component analysis, but unfortunately, the vast majority center on a small corner of the problem space, such as license management, or vulnerability detection, and miss the bigger picture. How much does traditional threat intel data really do to protect customers in this space, if most malicious packages that get discovered tend to remain up and running for years, with dozens of daily downloads? Given the sheer size of the issue, and the volume of code being dealt with, simply hiring enough staff to monitor and maintain upstream packages seems totally infeasible. With all of that in mind, there's a clear need for a new approach.
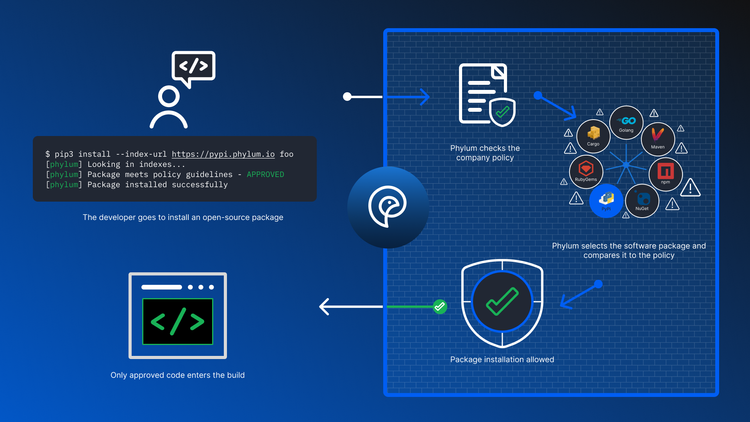
Phylum
With all of that in mind, Phylum's product line addresses each of the above issues: vulnerabilities, behavioral and reputation analysis, repository health and code quality, in addition to license management (among others). We provide both snapshot-in-time analysis (based on the current dependencies in use on a given project), in addition to continuous monitoring - allowing issues to be quickly identified before they make it into production, whether they come from a package update, or existing authors upstream.
Not Just Insights
Phylum's product provides innovative ways to solve upstream issues, and move the bar well beyond simply "Providing Insights". Not only are we working hard to provide automated problem mitigation tools, but we are also in the process of rolling out a service to help resolve upstream issues at scale (currently in Beta at the time of writing).
In short, Phylum can give you confidence in your upstream dependencies - both now, and as your requirements grow.