What Happens to Author Reputation When Malicious Packages are Taken Offline?

Overview
There has been an unprecedented rise in malware identified throughout the open-source ecosystem. Over the last several months alone, thousands of bad packages have been removed from package managers for typosquatting or for containing overtly malicious content, such as password or credential stealing code.
When an open-source package is flagged and removed for malicious behavior, what happens to the author’s other packages?
Absolutely nothing.
Case in Point
A clear example of this type of event occurred in July 2021. An open-source contributor published a JavaScript package which, on installation, extracted and exfiltrated stored passwords from the Chrome web browser. The original incident is detailed here.
While this package was discovered and removed, the response to the incident stopped there. This type of incomplete response highlights a major capability gap in general understanding of the software supply chain.
Looking back at the July 2021 event, which by all observations appears to be viewed as resolved, we see several problems:
- The developer in question is still active and able to publish new packages without oversight.
- The developer in question has 20 other active packages in the wild available for use by unknowing developers and other packages.
- Potential users of packages authored by the developer in question have no reasonable mechanism to know of the developer’s past transgressions without specific knowledge of the event in July 2021.
No Governance
What does this mean for modern organizations, security policies, and the management of third-party code? Previously, it meant we could only hope that developers would keep track of all prior incidents and track associated authors to avoid depending on open-source software with significant author risk.
There is no current mechanism in NPM, GitHub or within any of the realm of SCA vendor products to correlate author behavior with endemic ecosystem issues, including the publication of active malware.
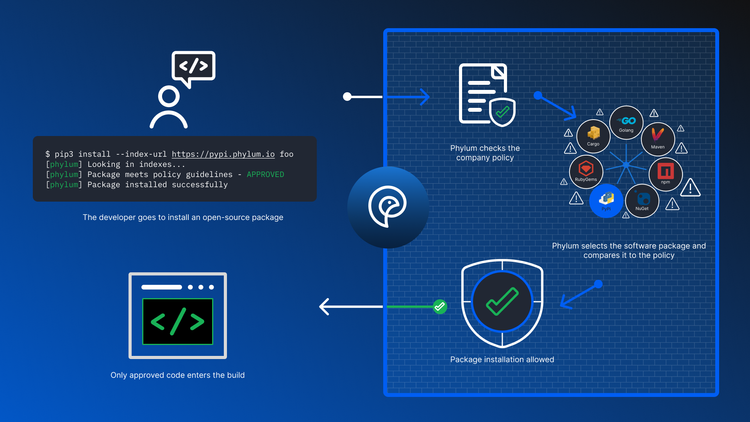
Phylum’s Approach
When we started Phylum, we were acutely aware of the challenges of tracking author behavior and security incidents. As a result, we carefully developed our Author Risk and Reputation score to integrate data from occurrences, such as the event discussed above, into an actionable score. This score enables users to defend themselves and their software from bad actors in the open-source ecosystem. Generating an Author Risk and Reputation score, however, requires thoughtful analysis that reflects author behaviors in a way that is useful to end users. We believe these efforts are a necessity, however, because reliance on untrusted code from strangers on the internet is here to stay.