An Introduction to Open-Source Software Supply Chain Risk

The Phylum Research Team turns four this month, and regular readers of this blog have seen how our team has exposed a wide variety of open-source malware campaigns. We have tracked down authors and their packages across a spectrum of maliciousness — from mischievous developers and petty thieves to a red team staging a major exercise and even nation-state activity. Currently, our automated software supply chain security platform has scanned over 1 billion files in nearly 34 million packages in seven ecosystems: npm, PyPI, NuGet, crates.io, RubyGems, Golang, and Maven Central. And, while we will continue to publish new findings, we want to take this opportunity to reflect on what we have learned over the past four years about the risks impacting your software supply chain.
--cta--
Risk has been defined as “the possibility of something bad happening”. Our extensive experience with malware in open-source software has convinced us that it is the most obvious and worst example of risk in the software supply chain. Other bad things, however, can and do occur in open-source software, and this blog is an introduction to a multi-part blog series that seeks to answer the question:
What are the greatest risks to your software supply chain?
This blog post will explore this question from first principles with as little prior knowledge as possible. Then, once we have laid this foundation, future blog posts will elaborate on individual aspects of these risks that the Phylum Research Team has built into a mental model of risk in software supply chains.
Join us as we begin this deep dive.
Open-source software
At a simplistic level, all software, or code, is ultimately a binary sequence of 0s and 1s that a machine can execute. This machine-executable binary sequence is one reason software is also called a binary. Very few humans have, or will, ever write pure, machine-executable code at its lowest level. Exceptions are as rare as they are significant.
Rather, software originates as source code, human-readable code that a machine cannot execute. It is fed as input to other software that translates the human-readable source code into the machine-executable code. When functioning properly, the machine executes the software precisely as the code dictates. Simply put, machines do not need source code; humans do.
Machine-executable code is opaque and unfit for human consumption. Human-readable source code exists as a communication between humans about the purpose of software; it explains what software does and how it does it. The initial communicant is the author of the software, the software developer. Everyone who learns to write code at some point asks themselves, “What was I doing or thinking?”, and source code provides an answer. Beyond the inner monologue, however, source code communicates to others the intentions and methods of the software.
When the group of communicants is restricted to certain people, for example for proprietary reasons, source code is colloquially said to be closed-source. Distributors of closed-source software primarily provide the machine-executable code — the functionality of the software and no more — without providing the human-readable source code that describes exactly how the software does what it does. The philosophical debate surrounding these terms and ensuing arguments over the validity of reasons for distributing closed-source code are beyond our scope here. It is enough for our purposes here to draw this simple distinction in source-code distribution.
On the other hand, open-source software (OSS) is ideally intended to have none of these closed-source proprietary restrictions. OSS distributors provide the source code that can be used to build the binary executable; they may also distribute a binary executable out of convenience to the user. In either case, the source code communicates to the user what the code is doing and how it does it.
ansi-styles - the most popular package on npm by downloads (360M weekly). Another developer can read and reason about this code to understand what the software does and how it does it.Of course, OSS is just as susceptible to miscommunication as every other form of human communication. But ideally, OSS provides more than mere software functionality. In contrast to the opacity of machine-executable code and an exclusive group of users in a closed-source ecosystem, OSS allows any software user to read and reason about the software.
Software developers derive the most benefit from having the software’s source code because it gives a developer the ability to do many other things beyond other software users. The developer can, for example, verify that the software’s functionality matches what the source code describes, find and fix flaws, and modify or extend the software’s functionality. Much more can be said here, but it suffices for us to focus here on the occasion when a software developer creates a link, i.e., a dependency, between someone else’s software and their own.
Software supply chains
A supply chain is “the system of people and things that are involved in getting a product from the place where it is made to the person who buys it,” and software developers are the initial and essential parts of this system. While it is possible (and sometimes even useful) to write software from scratch, most software is written out of necessity by using other software that exists prior.
For example, consider standard libraries. Many programming languages come with collections of functions that perform fundamental tasks such as writing files to disk, printing text to a screen, or sending information across a network. Software developers need to spend their time fulfilling software development requirements; it is too onerous and error-prone to write individual custom versions of such functions. So, they depend on standard libraries to get their design requirements done.
When a standard library does not exist to perform some task that their requirements demand, the developer must decide whether to create new code or to seek an alternative on which their code will depend. This choice is precisely where a fundamental link in a software supply chain is forged and where many forms of risk are introduced.

Code that depends on other code inherits all of its risks, and often, dependencies themselves have dependencies. This is the transitive dependency problem that the Phylum research team has written about in an earlier installment. It suffices here to see that a single software package may have many dependencies besides its immediate ones, each carrying potential risk.
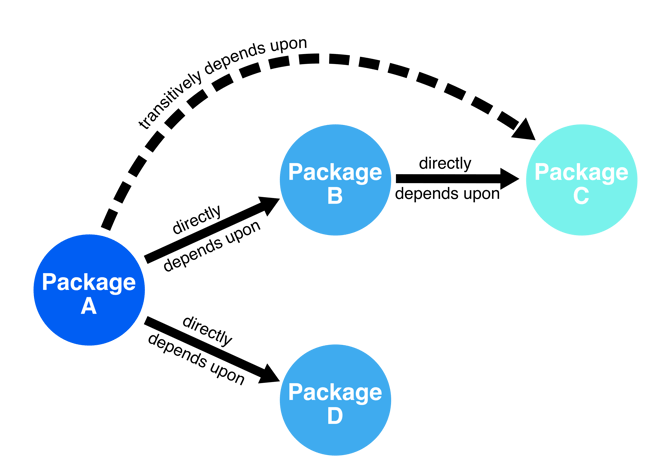
More bluntly, every code base in every software development environment assumes the sum of all the risks contributed by every developer of every dependency. This is true regardless of whether or not the source code is provided. A CISO may take comfort in the fact that their vetting process in hiring developers gives them a sense of control over these risks, but this does not account for the hundreds or even thousands of developers (strangers from the Internet, as we say at Phylum) over whom they have zero control wherever OSS is used.
As a final comment before we turn to a more systematic approach to these risks, note that this choice to introduce a dependency is often the correct choice because the task is so complex that the benefits to the developer overwhelmingly outweigh the risk introduced. For example, a data scientist investigating some phenomena should not waste their time writing a scientific computing library. The details needed to implement this correctly require, at a minimum, an expert’s knowledge of the programming language, numerical analysis, and the specifics of the machine’s architecture. If anything, implementing a bespoke scientific computing library would likely introduce more risk. Instead, the correct choice is to import a well-documented and tested scientific computing library as a dependency and get on with their investigation.
For well over the better part of a century, this scenario has been repeated over and over again to the point where we now have a superabundance of dependencies, which are innumerable links in our software supply chains. The Phylum Research Team has written extensively on the complexity of our software supply chains, the scale of which rivals global trade and Twitter. Many have tried to simplify this complexity by analogy to our physical supply chains, however, this comparison has catastrophic flaws that are outside our current scope and are better suited for another blog post. What we focus on here is the risk incurred by the trade-offs the developer makes by introducing open-source software dependencies. There is no free lunch.
Open-source software supply chain risk
We opened with the statement that risk is the possibility of something bad happening. Some OSS advocates claim that the risk is inherently less simply because the source code is provided. This might be true if every developer investigated every line of code in every dependency in their code, but this is laughably infeasible. A software developer has neither the time nor inclination to ever do this kind of review in totality. And so, bad things occur in OSS.
The most obvious and worst thing that can happen is malware – code that executes something other than the user’s intent to harm the user. Phylum considers malware the most significant and immediate risk to your software supply chain because the harm is bad 100% of the time. There are other forms of badness besides malware, however, where the harm may not be immediate nor even likely if it occurs at all. The software can be bad because it is poorly engineered. It can open an organization to legal liabilities. Or, it can be vulnerable to a potential exploit that could later enable malware.
Unlike malware which clearly and demonstrably harms the user, these other categories are much more subjective and require a more nuanced discussion. Nevertheless, we broadly categorize the risks in a software supply chain into four domains:
- Malware
- Engineering
- License
- Vulnerability
These categories are useful, even if the boundaries between them are infrequently crisp. The Phylum Research Team has found that we can find a home in this model for each kind of bad thing that a human can introduce in code. Risks from natural phenomena such as tornados or solar flares or human effects outside of code such as power outages or political unrest, however important, are outside the scope of this model.
Our model is based on what we can infer from the published source code, its associated metadata, and any other external data related to the code. This collective evidence is the basis of our evaluation of the possibility of something bad happening when a particular code package is introduced into a software development environment. And because humans are the primary agents introducing these risks, we can say something definitive about the person or persona responsible, the author, which is itself a fifth domain of risk, informed by the other four.
- Author
Phylum's risk model
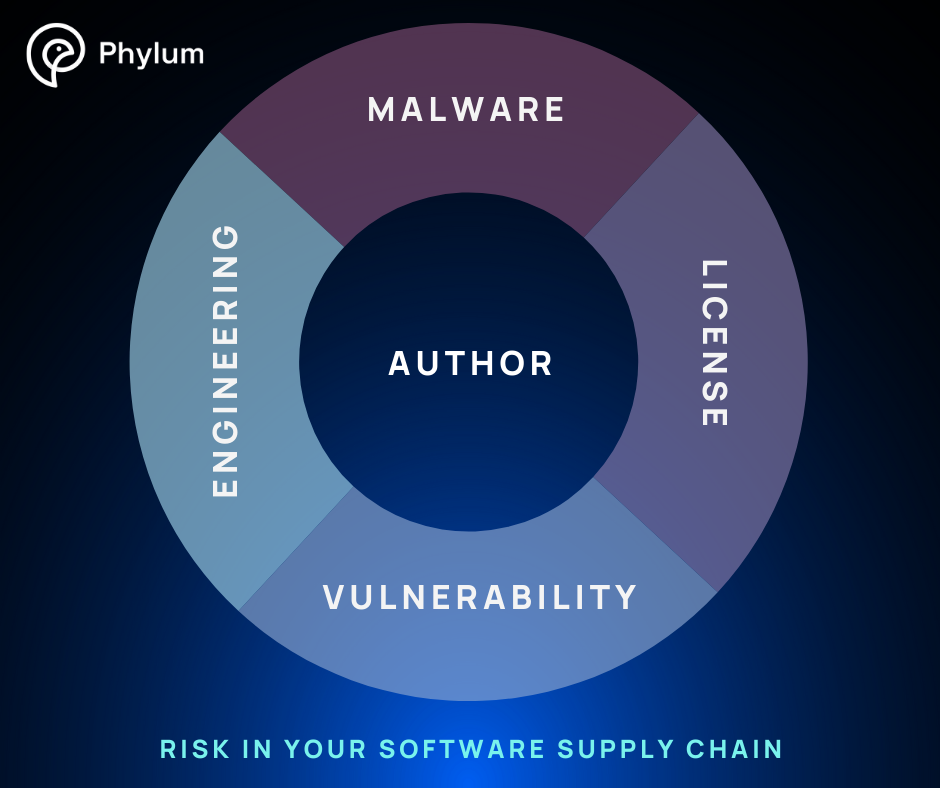
Malware risk, engineering risk, license risk, vulnerability risk, and author risk - four whats and a who - this model encapsulates how Phylum identifies and characterizes the possibilities of something bad happening in your software supply chain.
Future blogs in this series will focus on one of these risk domains in your software supply chain. The next installment will be on malware — stay tuned. Subscribe to the Phylum Research Blog if you want to be informed immediately when we publish the next blog in this series or other significant findings that could be impacting your software supply chain.