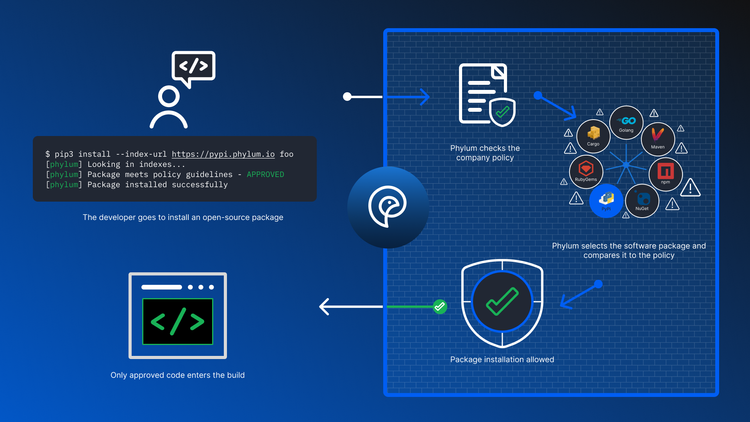
Managing Software Supply Chain Security Risks

Over the last year, software supply chain security has gone from a relatively niche topic to a major concern for organizations everywhere. Incidents have skyrocketed - increasing by over 400% last year - and vendor messaging has pivoted to discuss supply chain security, but the broader questions still remain unaddressed - what is the software supply chain, what about it has changed that is driving all of these new attacks and issues, and what do we do about it?
The Software Supply Chain
Just as physical manufacturing incorporates inputs, processes, and machinery to create finished products, software similarly incorporates a set of “raw inputs”, processes, and machinery to create finished software products. There are a few stark differences, however - while some of these are things that are relatively straightforward to build internal controls around, many of them (not the least of which being the inputs) rely on fundamentally untrusted developers.
Software Inputs
This area currently represents by far the largest attack surface in the software supply chain. While this was a relatively manageable area a few years ago, it has increased drastically - with modern projects growing from tens or hundreds of third-party dependencies five to six years ago well into the thousands today. Additionally, the types of threats emerging here have evolved substantially - while previously the primary concern was around using old versions of packages (as seen with the Equifax breach), we’re now seeing a host of new types of issue emerge - including fundamental flaws in package management infrastructure to problems driven by underproduction and a fundamental lack of investment and oversight, which has also contributed to the emergence of other major issues, such as Log4J. To make matters worse, there has been a massive increase in overtly malicious software appearing in the open-source ecosystem. This has appeared both with the publication of new malicious packages, which is bad enough by itself, but also has made a rash of recent appearances through account compromises in some of the most popular libraries in the open-source ecosystem.
Processes
While the processes behind developing and managing software are becoming increasingly important, they are also generally fairly well understood. Many of the basics (such as branch protection and change management) are covered through commodity security certifications such as SOC2. Some additional controls can provide real, meaningful protection here - commit signing being the biggest - to make sure that developer account compromises are less likely to result in adverse organizational impacts. Some tools are also frequently leveraged here to help maintain high-quality software and alleviate common issues during the development process.
Machinery
So, what exactly does machinery mean to software development? In this case, it covers the essential tools leveraged in automating modern software development. While it is common to confuse this with things like Kubernetes or other Infrastructure as Code (IaC) components, what this really refers to is the tools and components that run inside of a modern build pipeline. What does a modern build pipeline look like internally? Generally, it will consist of at least four distinct groupings of components: * Containers - which run the steps associated with the pipeline * CI/CD Steps - which define the actions that happen inside of the build pipeline * Build & Test - these components are tied indelibly to processes and are defined by the organization. Usually, these are the steps required to build software components and ensure that they are operational before a migration to production. Some of the other components that may appear here would include build tools and test frameworks used to generate the software that actually ends up in production and test its functionality. * Third-Party Tools - Finally, a suite of third-party components are generally added to perform additional testing, validation, and security to the build pipeline and process.
What makes this particular space interesting is the fact that, much like software inputs, it is also all but undefended - and has also become a point of significant interest for attackers.
The Software Supply Chain
Now that we’ve spent a bit of time examining the software supply, and its associated attack surface, how do we work to defend it? Let’s first spend a bit of time looking at the existing controls, and how they map to this threat model.
Software Supply Chain Security Tools
As the entire space surrounding software supply chain security is very new, a lot of confusion is being created by mixed messaging and vendor materials. Fundamentally, however, current offerings generally fall into the following categories:
- Inventory- This class of product has been popularized by the Software Composition Analysis (SCA) category of tools and by container-centric products like Anchore. These tools essentially focus on generating an inventory of subcomponents.
- Internal Code Scanning - Whether considering commodity SAST solutions, more recent IaC scanning tools, or secrets detection capabilities, these capabilities essential focus on scanning internally developed code.
- Attestation - This is a new, emerging category of control, but essentially covers modern frameworks such as SLSA - which provide a set of tools to manage essentially “tamperproofing” libraries and artifacts as they traverse the build pipeline.
Provenance
prov·e·nance (noun) - the place of origin or earliest known history of something…
So, what exactly does provenance imply? Simply put, it involves developing an understanding of where each component comes from, what its history is, who was involved, and what its inputs are. While this may seem somewhat trivial at first glance, it has become nearly impossible in recent years. Not only would someone (or a team of someones) need to fully audit thousands to tens of thousands of packages, as it turns out, this isn’t a problem that you can leverage a one-time analysis to solve. Package versions change constantly, and while this can be mitigated to a degree by processes (such as version pinning - or electing to use a very explicit set of versions of an upstream library), the protection provided by this approach is incomplete at best. Similarly, utilize a cache of packages also has sharp edges - attacks like dependency confusion and repojacking still easily circumvent these types of controls.
Automation
In many ways, the continued automation of software development has actually made this problem much worse. Not only has it effectively created yet another dimension in the software supply chain that needs to be addressed (the “machinery”), but it has also effectively made keeping up with changes to third party dependencies and components all but impossible. As both software ecosystems and the number of software developers continue to grow at an increasing rate, and the number of total security professionals in the labor market (much less ones with the specialized skillsets required to perform software project audits) continues to lag demand, it’s clear that the ability to proactively screen third-party packages is unable to keep pace. What this effectively means is that taking an inventory-style approach to input management will by definition have a substantial lag time when a major incident (such as an account breach) occurs, which turns a simple-to-identify problem into a severe security incident.
Addressing the Issues
So, given that there is a clear, substantial gap here, how do we work to address the issue and develop a continuous approach to understanding the provenance of components as they are released? While there is no simple answer, the only real solution is better automation. Not only has the lack of visibility into the components of the software supply chain has created massive opportunity for future attacks, but there is no real strategy to proactively avoid problems without automated controls. Additionally, many of these new classes of risk simply can’t be managed through older mechanisms. Not only do we need to think about how we more proactively identify problems, but we also need to spend some time thinking about how to best integrate them into modern development processes. When development organizations push hundreds to thousands of builds a day, the cost of wrangling findings becomes very high if builds break every time a new, relatively minor issue is found. In summary, given that we have a rapidly evolving ecosystem full of risks, and a clear lack of manpower to consistently address them before they become issues, we need modern tools that can answer the following questions:
- What is the risk implied by using components in the development of business-critical software, including updates to components that may not yet have had a thorough audit?
- How can I ensure that using these controls won’t slow down the pace of development?
- How can we leverage machine learning to ensure that we stay ahead of threats?
- What can be done to encode business risk into the software development process?
- Can understanding (and mitigation) of risks and existing issues be pushed as far left in the software development process as possible?
Gaining a solid understanding of these questions provides a solid foundation from which to address critical gaps in the security of the overall software supply chain. Providing insight into risks in a way which can operate at the speed of modern development is critical to ensuring that problems are identified before becoming significant issues. Additionally, software development and application security teams demand actionable insights and the ability to build policy that can encode both their risk profile, and ensure that security findings don’t get in the way of software development. While this is certainly a delicate balance to maintain, there is no other real path to ensuring that problems are identified, prioritized, and remediated effectively before making it into production systems.
Relevant Reads:
NPM Malware Report – Phylum