Report: 2022 Evolution of Software Supply Chain Security

Open-source threats are damaging, shockingly unsophisticated and probably already escalating through your software.
In early 2020, an ambitious group of developers assembled to tackle the biggest cybersecurity challenge they had ever encountered – securing the software supply chain. They founded Phylum and got to work. Fast forward to today: it’s been about a year since Phylum launched its software supply chain security platform, and the team has learned a lot.
Phylum’s 2022 Evolution of Software Supply Chain Security Report covers how software supply chains work, why you need to worry about the open-source ecosystem as an attack entry point, the truth behind attacker motivations, and what to expect in 2023.
What is a software security supply chain?
A software supply chain is anything, everything, anyone and everyone that has access to your code throughout the software development lifecycle. This includes components, cloud services, authors, repositories, libraries, codebases, packages and more. There are threats lurking at every development stage.
Understanding the attack surface
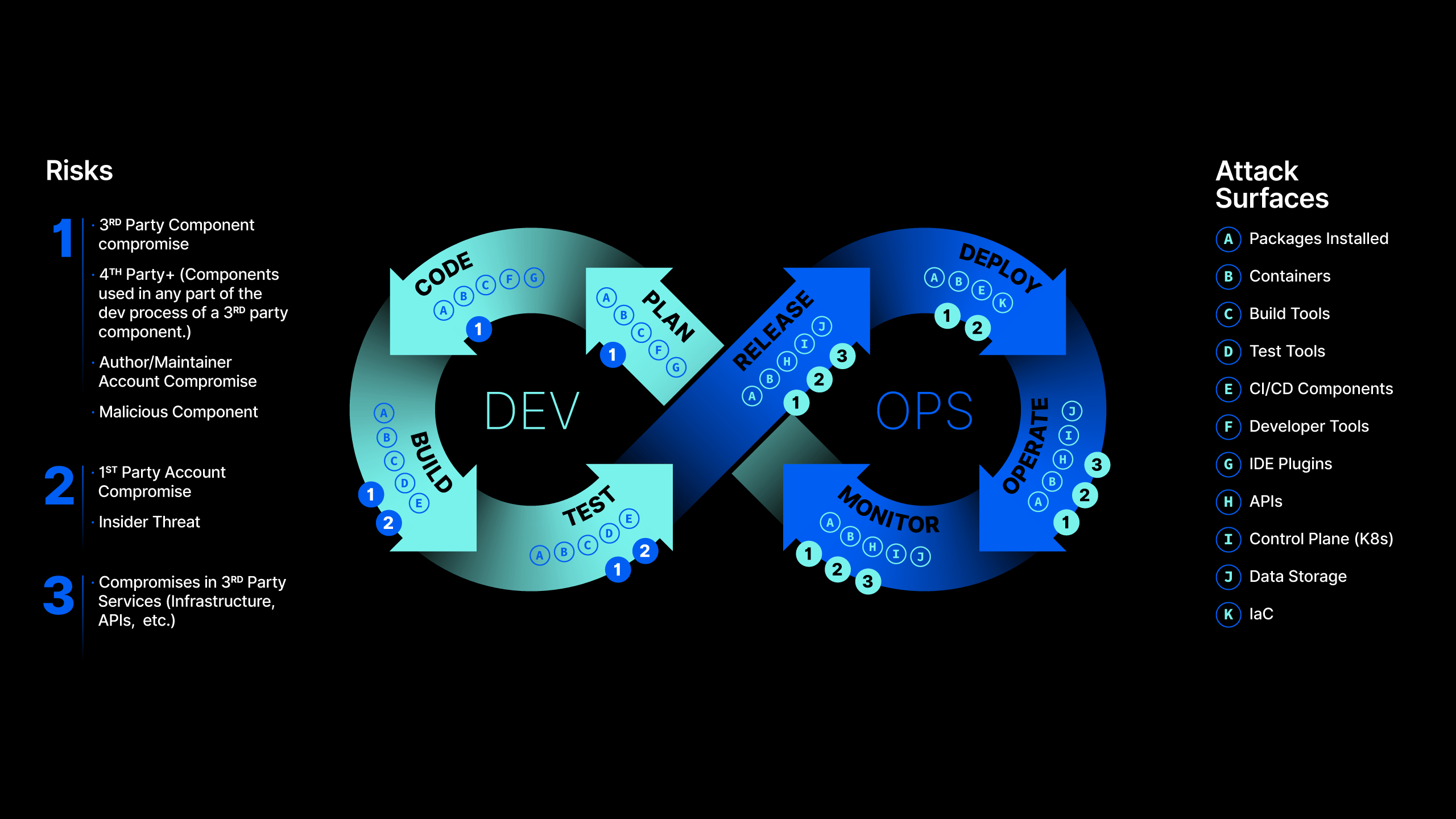
The open-source ecosystem is the perfect entry point for an attack. Security teams have very limited visibility into the process and no control over the developer workstations. Even the most unsophisticated attacks can go undetected, and their impacts are felt far downstream through data breaches, infrastructure compromises and other harmful outcomes.
At each step of this process, every open-source component exposes the developer to risks, which Phylum classifies into five domains:
- MALICIOUS CODE - Code that someone has authored to intentionally exert their will over the intentions of the developer. There are vast motivations and methods behind malicious code.
- SOFTWARE VULNERABILITIES - Code that does something other than what the original developer intended. The difference between malicious code and vulnerable code is intent. Vulnerable code is usually the result of human fallibility, not malice.
- ENGINEERING RISK - This refers to questions pertaining to your code like:
- How well can the code be reasoned about?
- How reliable is the code base (i.e., has it been well-tested)?
- How maintainable and extensible is the code?
- LICENSE MISUSE - The legal aspects of the open-source software. For example, certain software licenses require that source code be released, and this could create real intellectual property problems for a commercial enterprise.
- AUTHORSHIP RISK & REPUTATION - The “who/what/where” of open-source software:
- Who wrote it?
- What are their red flags?
- Where in the world is the author?
2022 Software Supply Chain Security Trends
Phylum analyzes open-source packages’ source code and metadata as they are published into several popular ecosystems: NPM, PyPI, RubyGems, Nuget, Golang, Cargo and Maven. This year, we analyzed 627M source files across 11M package publications. Of these packages, we have identified and reported 1,216 malicious packages. 70% of this malware was published to NPM, the most active ecosystem.
Developers are the new high-value targets
The battle between security teams wanting more visibility and developers wanting to code without interruptions or impediments from obstructive security tools has caused noticeable friction between these two teams. Attackers are exploiting this friction to gain an advantage in targeting developers directly. Our findings show that 99% of malicious open-source packages are designed to attack developer workstations and CI/CD build agents.
This year, we have seen developers fall victim to:
- Stolen credentials and secrets
- Compromised workstations
- CI/CD attacks
- Malicious packages in source code
Malicious payload execution techniques varied between threat actors; nearly all malicious packages gained a foothold via code triggered during package installation (e.g., in the setup.py in PyPI or a postinstall hook in NPM). This is a worrying indicator that developers are, in fact, the new high-value targets.
Open-source attacks are increasing and evolving
Below we discuss some of the most popular tactics that we have seen this year at Phylum, including a new hybrid approach:
Namesquatting
When a malicious author chooses to create a new package, it is necessary that they entice or deceive a developer to install that package. One way to do this is with namesquatting - that is, naming a package very similarly to an existing, legitimate package. Some common variations of this are typosquatting, combosquatting, and brandsquatting.
Typosquatting attempts to take advantage of human errors in typing. For example, a developer wants to install the package react but types raect instead. A malicious actor has a package named raect uploaded to the repository, and this mistake delivers his malware. Typosquats are easy to identify, but they remain popular for the simple reason that they are effective. Typosquatting accounted for over a quarter of the delivery mechanisms for malicious packages identified by Phylum, with 26% of published packages attempting to masquerade as known good software libraries. Phylum reported on three large-scale campaigns targeting NPM and PyPI, with many smaller campaigns occurring during the last six months of 2022.
Combosquatting differs from typosquatting by naming a package with a plausible, but fake name closely related to that of a legitimate package. For example, pytz is a legitimate Python package, but pytz3lib is a plausible fake since many python packages include a 3 in their name to indicate compatibility with Python 3. Also, lib is an innocuous addition to a package name.
We posed four sample namesquats to the audience during the most recent research roundtable. Both are names of Python packages, but only one of them is a legitimate package.
- requests vs. reuqests
- django-server-guardian-api vs. django-server
- urllib vs. urllib3
- python-openssl vs. openssl-python
Unsurprisingly, the first one did not fool anyone. Everyone correctly picked the legitimate package. The results for the remaining three examples were more startling.
- ✅requests vs. ⛔reuqests
- ✅django-server-guardian-api vs. ⛔django-server
- ⛔ urllib vs. ✅urllib3
- ⛔python-openssl vs. ✅openssl-python
You might be thinking “I’d never fall for something this obvious,” yet this is one of the most successful methods we’ve seen to date. To show just how easy it is to fall for this technique, see how people responded to the poll in our recent research roundtable - three out of the four examples we shared fooled most attendees.
Closing out this namesquatting discussion, we have also seen attempts to exploit the trust in the name recognition of an established brand, i.e., brandsquatting. We witnessed a Python package named mozilla published to PyPI earlier this year. It was immediately obvious that the package had nothing to do with the Mozilla Foundation, and it was taken down after we reported it.
Obfuscation
A fundamental principle of distributing open-source software is transparency. Source code that is transparent can be read and reasoned about by others in the community, and this enables the collaboration that fuels open-source software development. Alternatively, code that is difficult to read or difficult to understand hinders collaboration and is seemingly antithetical to open-source software.
Malicious attackers employ source code obfuscation to render their code opaque. A code obfuscator is a program that accepts a source code file and produces a new source code file that has mangled names and strings, dead code injected, and circuitous logic added. When the obfuscated source code file is executed, it ostensibly behaves in the same manner as the original file.
Attackers may employ their own obfuscation scheme, but typically we see them using any one of the numerous obfuscators that are freely available on the Internet. In either case, the intent is always the same: hide the intended function of the code. Where Phylum has found malicious code is almost always in the context of many diverse layers of obfuscation, with the most frequent location being in the installation code.
It is important to note that code obfuscation is not always malicious. For example, we have seen obfuscation used to hide intellectual property. This is not a particularly good policy since obfuscation can only hinder, not prevent, static source code analysis. Some deobfuscation programs are quite capable at unwinding obfuscated code. Dynamic code analysis can also reveal the intended purpose of the code. We have also seen examples of obfuscated code where we have speculated that the intent is to hide activity that is frowned upon by certain authoritarian governments. Even though we do not characterize these uses as strictly malicious, any code that does not explicitly reveal its purpose introduces risk into a development environment.
Dependency Confusion
Throughout 2022, we also witnessed a worrying increase in dependency confusion attacks targeting specific organizations across multiple industries.
In early 2021, a bug bounty researcher built the first proof of concept of such an attack and successfully executed his own code inside more than 35 different organizations. Later attackers have been caught targeting popular e-commerce platforms, online chat services, banks, and other financial institutions. In several cases, Phylum contacted the affected organizations and provided vital information on the attackers’ tactics, techniques, and procedures (TTPs).
A dependency confusion attack can occur when a package in a private registry does not exist in a public ecosystem's registry. Many package managers that are used in build tooling check public registries before private registries when downloading and installing packages. If an attacker learns the name of a package in someone's private registry, they can upload an identically named, but malicious, package to a public registry. Developers can then mistakenly include the malicious public package in their software instead of the safe private package.
This reliance on and exploitation of misconfigured internal build servers makes dependency confusion attacks much more difficult to detect than namesquatting-based attacks. Without deep knowledge of the build pipeline or awareness of where a package installer is looking first, developers are unlikely to realize that they got the wrong package until after it is too late.
Sporks
We coined the term spork, a portmanteau of spoof and fork, to draw a distinction between the traditional methods that we discussed earlier (create a new package or compromise an existing one) and a hybrid tactic that we have observed to be growing in popularity among malicious actors.
It is trivially easy to create a new software package. This low barrier to entry appeals to the malicious actor who does not want to unnecessarily exert any additional effort to achieve their goal. Many amateur attacks on open-source software are successful simply because no one took even a cursory glance at the source code before installing it, which would have revealed the software was not operating as advertised.
In order to raise the apparent legitimacy of their malicious packages, actors have taken to creating sporks or sporked packages to distribute their malicious payloads. A spork is created like this: an actor finds a known, preferably popular, package in an ecosystem and creates a fork of that package – an exact duplicate of the original. Now, the original package name is unavailable, so it is necessary to spoof the namespace of the package in some way that entices and deceives a developer into installing their spork (along with their malicious modifications. Now, the actor has co-opted all the apparent legitimacy of the original package without having to go through the difficult work to create their own plausible code or to compromise the legitimate package. When inspecting the primary intent of the code, it looks like the real thing, because it is a fork of the legitimate project. It is the best of both worlds.
The Phylum Darwin Award Winners are…
As we mentioned earlier, malicious authors don’t have to work that hard to succeed, but that doesn’t mean they didn’t make some creative attempts. Let’s honor them, shall we?

Evolutionaries
These authors made valid attempts, but still got caught. They’ll likely keep evolving their tactics and we predict we’ll see more of them in 2023:
Compromised Packages Targeting Cryptocurrency Exchanges
In September 2022, attackers published malicious versions of legitimate packages via compromised accounts. These packages targeted the cryptocurrency exchange DyDx. The attack was particularly egregious as it attempted to exfiltrate infrastructure information which, if successful, would have allowed the attackers to pivot further into critical infrastructure.
W4SP
In early July 2022, Phylum witnessed new threat actors in the PyPI ecosystem testing early-stage campaign techniques. These actors leveraged typosquatting to infect developer workstations with the W4SP credential-stealing malware. In late October, the actor published several dozen typosquatted packages with slightly updated and improved delivery and obfuscation. These attackers changed tactics slightly after initial detection by attempting to masquerade as legitimate organizations on PyPI by publishing, for example, packages under the username “Mozilla.”
Stealing Developer Cryptocurrency
With monetary rewards to be had, it was only a matter of time before we saw widespread attempts to steal cryptocurrency from developers. In Nov 2022, Phylum identified threat actors attempting to install malware by way of malicious PyPI packages that would swap legitimate cryptocurrency wallet addresses with addresses controlled by the attacker. Whenever a developer copied a wallet address (presumably before transferring funds), the address would be surreptitiously replaced, causing the developer to send funds to the attacker instead of the intended recipient.
Widespread NPM Typosquatting Campaign
Early on Oct 2, 2022, Phylum detected a large-scale malicious campaign against NPM developers. The attackers published 127 packages typosquatting popular packages in the ecosystem. The attackers leveraged a preinstall hook that was executed during package installation. The malware would then download a second stage .lnk file, which contained a small Powershell script. Executing this would result in the theft of developer and infrastructure credentials.

Dodo Bird
This author made an attempt that never got off the ground, much like the flightless Dodo Bird, and may want to consider finding a new hobby:
Failed Obfuscation Attempt
On September 11, 2022, Phylum identified a new malware publication immediately after it was released. The malware made heavy use of Python obfuscation. The attacker was seemingly unaware that the obfuscator they selected required the obfuscator’s copyright to be left in place to function. A copyright that the attacker removed. This prevented the malware from being able to execute. Thwarted by their own attempts at obfuscation. Embarrassing.
What to Expect in 2023
Software supply chain attacks originating from the open-source ecosystem will significantly increase.
We found in 2022 that attackers did a lot of trial and error in the open-source ecosystem. It is a playground for bad actors who are testing the art of what is possible. We will see an increase in malicious authors as well as the number of attacks they execute.
Malicious authors will get bolder and more sophisticated, but dumb things will still continue to work.
As the number of malicious authors increases, so will the sophistication of their attacks. Bad actors will take what was learned from all the trial and error in 2022 and improve their methodologies. However, unsophisticated attacks will continue to be effective until organizations catch up on securing their software supply chains.
We will see a successful Ransomware attack be executed from an open-source ecosystem entry point.
We have already begun to see malware authors include well-known ransomware binaries in their open-source package publications. While rudimentary, this follows the common publish and iterate pattern we have seen attackers take over the last year, where they refine their techniques and up their sophistication. The monetary incentive coupled with the ease by which attackers can target specific organizations by way of dependency confusion ensure that this is only a matter of time.
Organizations will begin to embrace code provenance, but SBOMs are not the answer.
Code provenance requires an understanding of where each component comes from, what its history is, who was involved, and what its inputs are. However, the key is to be able to do this in a continuous manner as package versions constantly change. There is currently a lot of vendor hype fueling the market around creating Software Bill of Materials (SBOMs), but these will only provide a snapshot in time. Not to mention, there is not yet an agreed upon standard and nearly every field in the emerging standards is optional. To achieve true code provenance, organizations will need to embrace scalable automation aligned to their specific risk tolerances and threat models.
About the Phylum Research Team
The Phylum Research Team is made up of proven, seasoned security researchers, data scientists and software engineers. The team’s collective experience spans across government and the private sector, with team members making impactful contributions to startups, the intelligence community, federal policy and agencies like the Department of Defense.
The research team’s purpose is to explore new ideas and turn those into analytics that will ensure that Phylum remains the leader in Software Supply Chain Security. It isn’t enough that we have some cool new idea of our own or something that we are following in the security research community, we want those ideas to make a difference for our customers. In my experience as an applied researcher, this is a difficult chasm to cross. Some have even referred to it as the “Valley of Death” - getting an idea out of the research space and engineered into production. And so, we built our research team to overcome this challenge with a good balance of research and engineering.
Heuristics and rules are our internal parlance for all of the automation that goes into data collection, feature engineering, machine learning models, and other decision logic for finding the risks in the Open-Source Software Supply Chain. We built Phylum to scan entire ecosystems at scale, and so we automate everything that we possibly can to provide the broadest coverage.
About Phylum
Phylum defends applications at the perimeter of the open-source ecosystem and the tools used to build software. Its automated analysis engine scans third-party code as soon as it’s published into the open-source ecosystem to vet software packages, identify risks, inform users, and block attacks. Phylum’s open-source software supply chain risk database is the most comprehensive and scalable offering available. Depending on an organization’s infrastructure and appsec program maturity, Phylum can be deployed throughout the development lifecycle, including in front of artifact repositories, in CI/CD pipelines, or integrated directly with package managers. Phylum also offers a threat feed of real-time software supply chain attacks. The company is built by a team of career security researchers and developers with decades of experience in the U.S. Intelligence Community and commercial sectors. Phylum won the Black Hat 2022 Innovation Spotlight Competition, was named to Inc. Magazine’s 2023 Best Workplaces, and became a Top Infosec Innovator by Cyber Defense Magazine. Learn more at https://phylum.io, subscribe to the Phylum Research Blog, and follow us on LinkedIn, X and YouTube.